वेक्टर डेटाबेस क्या है?
By Sean Chen, 10 नवमबर 2023

यह लेख श्रृंखला "AI को AI समझाने दें" का हिस्सा है, जिसे GPT-4 जैसे बड़े भाषा मॉडल द्वारा मानव पर्यवेक्षण के तहत लिखा गया है। इस श्रृंखला का उद्देश्य विभिन्न पृष्ठभूमि के पेशेवरों को AI से संबंधित ज्ञान को आसानी से समझाना है। पहले भाग में व्यावसायिक दृष्टिकोण से ज्ञान बिंदु का महत्व समझाया गया है, जबकि दूसरे भाग में तकनीकी विवरणों की गहराई में जाया गया है।
जब व्यवसाय बड़े डेटा के युग का सामना करते हैं, तो वेक्टर डेटाबेस असंरचित डेटा में एक प्रकाशस्तंभ बन जाता है, जो तेज़ सूचना खोज के मार्ग को रोशन करता है। यह लेख आपको इस तकनीक के काम करने के तरीके और इसके व्यापारिक महत्व और प्रभाव को गहराई से समझने में मदद करेगा।
वेक्टर डेटाबेस का सिद्धांत और सार
वेक्टर डेटाबेस गणित में "वेक्टर" का उपयोग करके जानकारी संग्रहीत करता है। चलिए इसे एक जीवन के उदाहरण से समझते हैं: मान लीजिए आपके कमरे में कई अलग-अलग रंगों की गेंदें हैं, प्रत्येक गेंद एक प्रकार की जानकारी का प्रतिनिधित्व करती है। अब, आप चाहते हैं कि गेंदों को शेल्फ पर एक विशेष स्थान पर रखा जाए, और ये स्थान प्रत्येक गेंद के रंग की विशेषताओं को दर्शाएं। इसलिए, आप एक "रंग मानचित्र" नोटबुक का उपयोग करने का निर्णय लेते हैं ताकि आपको प्रत्येक गेंद का स्थान खोजने में मदद मिल सके। इस नोटबुक में, समान रंग की गेंदों को एक-दूसरे के करीब रखा जाएगा; जबकि विभिन्न रंगों की गेंदों को दूर रखा जाएगा।
वेक्टर डेटाबेस इसी सिद्धांत का अनुसरण करता है, यह पहले विभिन्न प्रकार की जानकारी (जैसे कि पाठ, चित्र या ध्वनि) को गणितीय वेक्टर में परिवर्तित करता है (जैसे कि पहले उल्लेख की गई गेंदें)। इन वेक्टरों की अपनी स्थिति होती है, जैसे कि शेल्फ पर गेंदें। जब आप किसी जानकारी के समान अन्य जानकारी को जल्दी से खोजना चाहते हैं, तो वेक्टर डेटाबेस आपको इस बहु-आयामी स्थान में सबसे निकटतम वेक्टर खोजने में मदद करता है (जैसे कि सबसे समान रंग की गेंद को खोजना)।
सरल शब्दों में, यह गणितीय तरीकों के माध्यम से जानकारी की विशेषताओं को स्थान में बिंदुओं के रूप में अमूर्त करता है, और फिर इन बिंदुओं के बीच की दूरी की गणना करके समान जानकारी को जल्दी से खोजता है।
महत्व क्यों है
कल्पना कीजिए, आप एक बड़े पुस्तकालय में एक विशेष पुस्तक की खोज कर रहे हैं, यदि प्रत्येक पुस्तक को केवल लेखक या शीर्षक के अनुसार व्यवस्थित किया गया है, तो आपको खोजने में बहुत समय लग सकता है। लेकिन अगर पुस्तकें "सामग्री की प्रासंगिकता" के अनुसार व्यवस्थित हैं, तो आपकी इच्छित पुस्तक समान विषय की पुस्तकों के साथ रखी जाएगी, जिससे खोज बहुत तेज हो जाएगी। यही वेक्टर डेटाबेस का महत्व है: वे बड़ी मात्रा में डेटा की खोज और विश्लेषण की दक्षता को अत्यधिक बढ़ा सकते हैं।
कैसे उपयोग करें
वेक्टर डेटाबेस का उपयोग करते समय, सबसे पहले एक डेटा सेट की आवश्यकता होती है, जैसे कि पाठ, चित्र या ध्वनि। ये डेटा "मशीन लर्निंग मॉडल" के माध्यम से "वेक्टर" में परिवर्तित होते हैं। फिर, ये वेक्टर वेक्टर डेटाबेस में संग्रहीत होते हैं। जब उपयोगकर्ता एक क्वेरी प्रस्तुत करता है, तो उस क्वेरी को भी वेक्टर में परिवर्तित किया जाता है, और डेटाबेस उस क्वेरी वेक्टर के सबसे निकटतम डेटा वेक्टर को जल्दी से खोजता है, जिससे उपयोगकर्ता को आवश्यक जानकारी मिलती है।
अनुप्रयोग
वेक्टर डेटाबेस का उपयोग उन कंपनियों द्वारा किया जाता है जिन्हें बड़ी मात्रा में डेटा को संसाधित करने की आवश्यकता होती है। इसमें प्रौद्योगिकी कंपनियां, वित्तीय संस्थान, स्वास्थ्य देखभाल संस्थान, और यहां तक कि खुदरा विक्रेता शामिल हैं। कोई भी संगठन जिसे "असंरचित डेटा के विशाल समुद्र से, आवश्यक जानकारी को जल्दी से खोजने की आवश्यकता होती है" वेक्टर डेटाबेस का उपयोग कर सकता है।
फायदे
वेक्टर डेटाबेस का लाभ इसकी उच्च दक्षता और सटीकता में है। यह बड़ी मात्रा में जटिल डेटा को जल्दी से संसाधित और पुनः प्राप्त कर सकता है, जो पारंपरिक डेटाबेस का उपयोग करते समय अक्सर असंभव होता है। इसके अलावा, वेक्टर डेटाबेस अस्पष्ट क्वेरी को संभालने में भी बहुत अच्छा है, जो मशीन लर्निंग और आर्टिफिशियल इंटेलिजेंस अनुप्रयोगों के लिए महत्वपूर्ण है।
चुनौतियाँ
विशेष रूप से बहुत बड़े डेटा सेट को संसाधित करते समय, बड़ी मात्रा में कंप्यूटिंग संसाधनों की आवश्यकता होती है। इसके अलावा, उन्हें सेट अप और बनाए रखने के लिए अत्यधिक विशेषज्ञता की आवश्यकता होती है। अंत में, डेटा की गोपनीयता और सुरक्षा भी एक महत्वपूर्ण विचार है।
वेक्टर डेटाबेस की मूल बातें समझने के बाद, चलिए अब हम चार्ट और वास्तविक मामलों के साथ वेक्टर डेटाबेस के संचालन को और अधिक ठोस रूप से समझते हैं!
विज़ुअल चार्ट के माध्यम से वेक्टर डेटाबेस का परिचय
हम बुनियादी अवधारणा चार्ट से शुरू करते हैं, वेक्टर डेटाबेस के संचालन के सिद्धांत को समझाने के लिए, फिर एक ठोस मामले का विश्लेषण करते हैं। नीचे इन दोनों भागों का वर्णन है:
संचालन सिद्धांत का चार्ट स्पष्टीकरण
- वेक्टर रूपांतरण चार्ट: यह चार्ट दिखाता है कि कैसे पाठ, चित्र या ध्वनि डेटा को वेक्टर में परिवर्तित किया जाता है।
- वेक्टर स्पेस चार्ट: बहु-आयामी स्थान में, प्रत्येक बिंदु एक वेक्टर का प्रतिनिधित्व करता है, यह चार्ट दिखाएगा कि ये बिंदु समानता के आधार पर कैसे एकत्रित होते हैं। हम विभिन्न श्रेणियों के डेटा को दर्शाने के लिए विभिन्न रंगों के बिंदुओं का उपयोग कर सकते हैं।
- क्वेरी प्रोसेसिंग फ्लो चार्ट: उपयोगकर्ता द्वारा क्वेरी दर्ज करने से लेकर परिणाम प्राप्त करने तक, यह फ्लो चार्ट पूरे पुनः प्राप्ति प्रक्रिया को दिखाएगा। इसमें उपयोगकर्ता क्वेरी का इनपुट, वेक्टर में रूपांतरण प्रक्रिया, डेटाबेस में वेक्टर का मिलान प्रक्रिया, और अंततः उपयोगकर्ता को लौटाए गए समान परिणाम शामिल होंगे।
ठोस मामले का विश्लेषण
मान लीजिए एक ई-कॉमर्स कंपनी है, जो अपने "उत्पाद अनुशंसा प्रणाली" की सटीकता और दक्षता को बढ़ाना चाहती है, लक्ष्य यह है कि जब उपयोगकर्ता उत्पाद खोजता है, तो वह जल्दी से सबसे प्रासंगिक उत्पादों को खोज और अनुशंसा कर सके।
मामले के कार्यान्वयन के चरण:
- डेटा संग्रह: कंपनी अपने उत्पाद डेटाबेस से डेटा एकत्र करती है, जिसमें उत्पाद विवरण, चित्र और ग्राहक समीक्षाएं शामिल हैं।
- वेक्टर रूपांतरण: मशीन लर्निंग मॉडल का उपयोग करके, प्रत्येक उत्पाद के विवरण और चित्र को वेक्टर में परिवर्तित किया जाता है।
- वेक्टर डेटाबेस निर्माण: इन वेक्टरों को वेक्टर डेटाबेस में संग्रहीत किया जाता है, और एक तेज़ पुनः प्राप्ति प्रणाली बनाई जाती है।
- उपयोगकर्ता क्वेरी प्रोसेसिंग: जब उपयोगकर्ता एक कीवर्ड क्वेरी दर्ज करता है, जैसे: स्पोर्ट्स शूज़, सिस्टम इस क्वेरी को वेक्टर में परिवर्तित करता है, और वेक्टर डेटाबेस में सबसे समान वेक्टर खोजता है।
- परिणाम लौटाना: सिस्टम सबसे अधिक समानता वाले उत्पाद वेक्टर को उत्पाद जानकारी में परिवर्तित करता है, और उपयोगकर्ता को प्रदर्शित करता है।
हम इन अवधारणाओं का वर्णन करने के लिए Python का उपयोग करेंगे। चलिए पहले चार्ट को देखते हैं: वेक्टर रूपांतरण चार्ट।
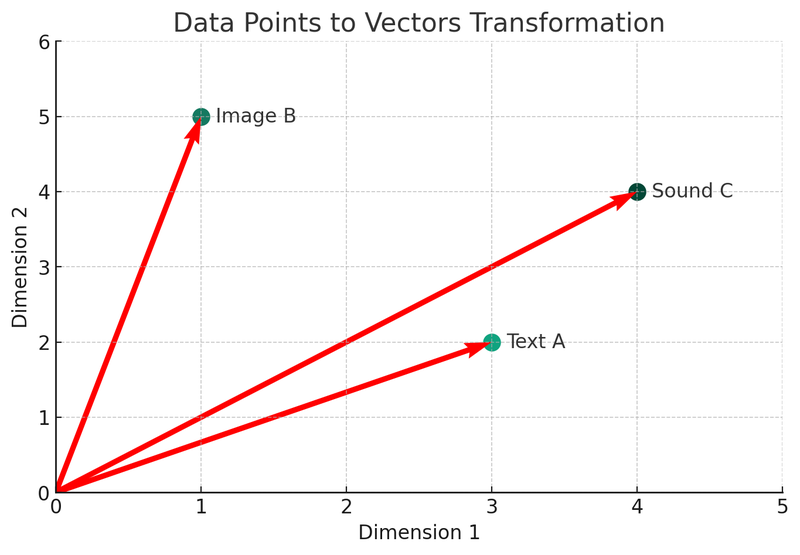
इस चित्रण में, हम देख सकते हैं कि तीन अलग-अलग डेटा प्रकार (पाठ A, चित्र B, ध्वनि C) को द्वि-आयामी स्थान में वेक्टर रूप में परिवर्तित किया गया है। प्रत्येक बिंदु एक वेक्टर का प्रतिनिधित्व करता है, अर्थात् मूल डेटा का गणितीय प्रतिनिधित्व। यह प्रक्रिया वेक्टर डेटाबेस के अनुक्रमण और पुनः प्राप्ति तंत्र का मूल है।
अगला, हम दूसरा चार्ट बनाएंगे: वेक्टर स्पेस चार्ट, यह दिखाने के लिए कि ये डेटा बिंदु (अब वेक्टर) बहु-आयामी स्थान में समानता के अनुसार कैसे एकत्रित होते हैं।
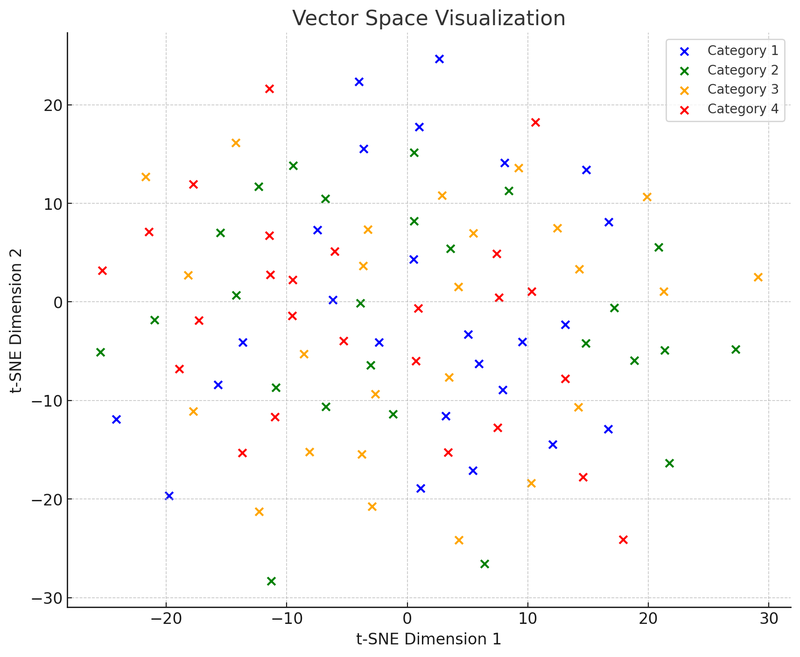
इस वेक्टर स्पेस विज़ुअलाइज़ेशन के चित्रण में, हमने t-SNE (t-distributed Stochastic Neighbor Embedding) का उपयोग किया है, जो एक सामान्य रूप से उपयोग की जाने वाली आयाम घटाने की तकनीक है, जो हमें उच्च-आयामी डेटा को द्वि-आयामी या त्रि-आयामी स्थान में प्रक्षेपित करने में मदद करती है, जिससे विज़ुअलाइज़ेशन में आसानी होती है। यह चार्ट 100 डेटा बिंदुओं (मूल रूप से 50-आयामी स्थान में) को द्वि-आयामी स्थान में घटाए जाने के बाद के वितरण को दिखाता है। मान लीजिए कि ये बिंदु चार श्रेणियों में विभाजित हैं, प्रत्येक श्रेणी को अलग-अलग रंगों में दर्शाया गया है, इस तरह का विज़ुअलाइज़ेशन यह समझने में मदद करता है कि वेक्टर डेटाबेस कैसे काम करता है: वे डेटा बिंदुओं (अर्थात् वेक्टर) के बीच की सापेक्ष दूरी के आधार पर समान डेटा बिंदुओं को एकत्रित कर सकते हैं। यह विशेषता वेक्टर डेटाबेस को पुनः प्राप्ति के समय "पड़ोसी" बिंदुओं को बहुत तेजी से खोजने में सक्षम बनाती है, अर्थात् वे डेटा बिंदु जो क्वेरी के सबसे समान हैं।
ई-कॉमर्स कंपनी के उत्पाद अनुशंसा प्रणाली का अनुकरण करने के लिए, हम एक सरलीकृत उदाहरण बनाएंगे, जिसमें शामिल होंगे: एक उत्पाद वेक्टर सेट और एक उपयोगकर्ता की क्वेरी वेक्टर। हम इन उत्पाद वेक्टरों के वेक्टर स्पेस में वितरण और उपयोगकर्ता की "क्वेरी वेक्टर" कैसे "सबसे निकटतम उत्पाद वेक्टर" को खोजता है, को चित्रण के माध्यम से प्रदर्शित करेंगे, ताकि उत्पाद अनुशंसा प्रणाली में वेक्टर डेटाबेस के अनुप्रयोग को समझाया जा सके।
चित्रण का मामले का विश्लेषण
पहले, एक सिमुलेटेड उत्पाद वेक्टर सेट उत्पन्न करें, फिर एक उपयोगकर्ता क्वेरी वेक्टर को परिभाषित करें। इसके बाद हम
एक चार्ट का उपयोग करेंगे यह दिखाने के लिए कि यह क्वेरी वेक्टर वेक्टर स्पेस में कैसे स्थित होता है और निकटतम पड़ोसी उत्पाद वेक्टर को कैसे खोजता है।
आइए इस प्रक्रिया को शुरू करें।
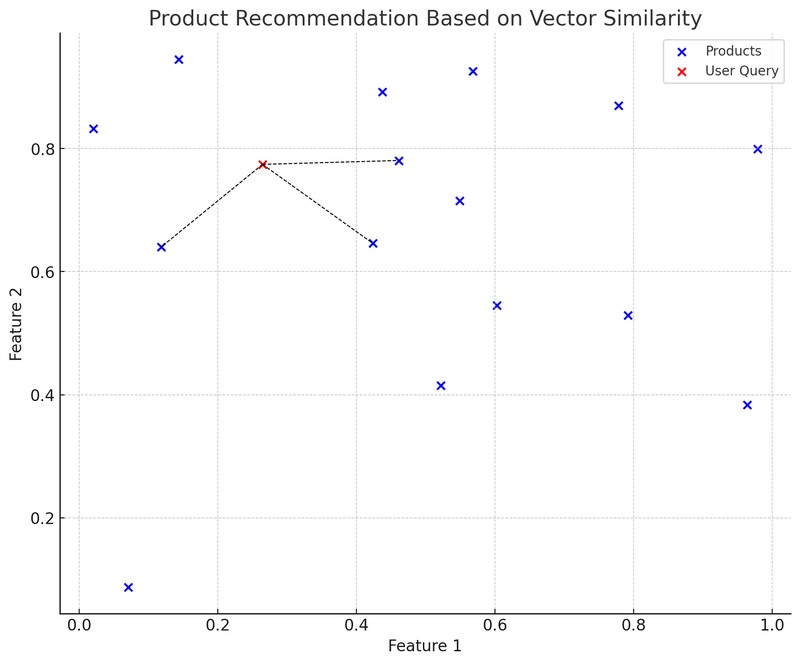
इस चार्ट में, नीले बिंदु ई-कॉमर्स प्लेटफॉर्म पर विभिन्न उत्पादों का प्रतिनिधित्व करते हैं, प्रत्येक उत्पाद का एक द्वि-आयामी विशेषता वेक्टर होता है। लाल बिंदु एक उपयोगकर्ता की क्वेरी है, जिसे समान रूप से एक द्वि-आयामी वेक्टर में परिवर्तित किया गया है। हमने K-D ट्री (KDTree) डेटा संरचना का उपयोग किया है ताकि "उपयोगकर्ता क्वेरी के सबसे निकटतम उत्पाद वेक्टर" को तेजी से खोजा जा सके।
चार्ट में, उपयोगकर्ता क्वेरी वेक्टर (लाल बिंदु) से निकटतम पड़ोसी उत्पाद वेक्टर तक की कनेक्शन (काली डॉटेड लाइन) यह दर्शाती है: अनुशंसा प्रणाली वेक्टर के बीच की समानता के आधार पर उपयोगकर्ता को ये उत्पाद अनुशंसा करेगी। यह वेक्टर डेटाबेस के वास्तविक अनुप्रयोग का एक सरलीकृत उदाहरण है: उपयोगकर्ता एक क्वेरी प्रस्तुत करता है, सिस्टम क्वेरी को वेक्टर में परिवर्तित करता है, और वेक्टर डेटाबेस में सबसे समान उत्पाद वेक्टर को तेजी से खोजता है, जिससे उपयोगकर्ता को संबंधित उत्पादों की अनुशंसा की जाती है।
इस विधि का लाभ यह है कि अनुशंसा की गति तेज और अपेक्षाकृत सटीक होती है, क्योंकि यह उत्पाद विशेषताओं की गणितीय गणना पर आधारित होती है, न कि केवल कीवर्ड मिलान पर। चुनौतियों में शामिल हैं: विशेषता वेक्टर को कैसे चुनें और समायोजित करें ताकि वे उत्पाद विशेषताओं का सबसे अच्छा वर्णन और प्रतिनिधित्व कर सकें, और "कोल्ड स्टार्ट" समस्या को कैसे संभालें, जैसे कि नए उत्पादों या कम सामान्य क्वेरी के लिए।
निष्कर्ष
आज के डेटा-संचालित निर्णय लेने वाले व्यावसायिक वातावरण में, वेक्टर डेटाबेस एक अद्वितीय और शक्तिशाली तरीके से बड़ी मात्रा में बहु-आयामी डेटा को संसाधित और पुनः प्राप्त करते हैं, जिससे वे आर्टिफिशियल इंटेलिजेंस और मशीन लर्निंग अनुप्रयोगों के लिए आदर्श विकल्प बन जाते हैं। खोज परिणामों की प्रासंगिकता को बढ़ाने से लेकर व्यक्तिगत उत्पाद अनुशंसा को बढ़ावा देने तक, वेक्टर डेटाबेस तेजी से विभिन्न उद्योगों के डेटा इंजीनियरों और प्रौद्योगिकी नवप्रवर्तकों के लिए एक मूल्यवान उपकरण बन रहे हैं। Appar Technologies के चित्रण और मामले के विश्लेषण के माध्यम से, हम आशा करते हैं कि हमने आपको स्पष्ट रूप से समझाया है कि वेक्टर डेटाबेस कैसे काम करते हैं, और वे इतनी तेजी से और सटीक परिणाम क्यों प्रदान कर सकते हैं।
वेक्टर डेटाबेस ने दिखाया है कि जब लोग डेटा को समझने और उपयोग करने के नए तरीकों की खोज करते हैं, तो वे कितने शक्तिशाली उपकरण और अनुप्रयोग बना सकते हैं। जैसे-जैसे तकनीक का विकास जारी रहेगा, हम उम्मीद कर सकते हैं कि वेक्टर डेटाबेस भविष्य के डेटा प्रोसेसिंग और विश्लेषण कार्यों में और भी महत्वपूर्ण भूमिका निभाएंगे।
यदि आप यह जानने में रुचि रखते हैं कि जनरेटिव AI कैसे उच्च गुणवत्ता वाले लेख उत्पन्न करता है, बड़े भाषा मॉडल को उत्पादों या उद्यम के आंतरिक प्रक्रियाओं में एकीकृत करता है, तो आप जनरेटिव AI विशेषज्ञ से संपर्क कर सकते हैं Appar Technologies, hello@appar.com.tw पर परामर्श के लिए अपॉइंटमेंट बुक करें।