Hvad er en vektordatabase?
By Sean Chen, 10. november 2023

Denne artikelserie, "Lad AI forklare AI", er skrevet af store sprogmodeller som GPT-4 under menneskelig overvågning. Serien er designet til at give personer med forskellige baggrunde en letforståelig indsigt i AI-relateret viden. Den første del forklarer betydningen af denne viden for erhvervslivet, mens den anden del går i dybden med tekniske detaljer.
Når virksomheder står over for big data-æraen, bliver vektordatabaser en lysende vej i den ustrukturerede dataverden, der oplyser vejen til hurtig informationssøgning. Denne artikel vil give dig en dybdegående forståelse af, hvordan denne teknologi fungerer, og dens betydning og indflydelse på erhvervslivet.
Principperne og essensen af vektordatabaser
Vektordatabaser bruger matematiske "vektorer" til at lagre information. Lad os tage et eksempel fra hverdagen: Forestil dig, at dit værelse er fyldt med små kugler i forskellige farver, hvor hver kugle repræsenterer en type data. Nu ønsker du at placere kuglerne på en bestemt plads på en hylde, og disse pladser skal kunne afspejle hver kugles farveegenskaber. Du beslutter dig for at bruge en "farvekort"-notatbog til at hjælpe dig med at finde hver kugles placering. I denne notatbog vil kugler med lignende farver blive placeret tættere på hinanden, mens forskellige farver vil blive placeret længere væk.
Vektordatabaser fungerer på samme måde. De konverterer forskellige data (som tekst, billeder eller lyd) til matematiske vektorer (ligesom de nævnte kugler). Disse vektorer har deres egen position i et flerdimensionelt rum, ligesom kuglerne på hylden. Når du hurtigt vil finde data, der ligner en bestemt data, vil vektordatabasen hjælpe dig med at finde de vektorer, der er tættest på hinanden i dette flerdimensionelle rum (ligesom at finde kugler med den mest lignende farve).
Kort sagt, ved hjælp af matematiske metoder abstraheres dataenes egenskaber til punkter i rummet, og ved at beregne afstanden mellem disse punkter kan man hurtigt finde lignende data.
Hvorfor det er vigtigt
Forestil dig, at du er i et stort bibliotek og leder efter en bestemt bog. Hvis hver bog kun kan arrangeres efter forfatter eller titel, kan det tage lang tid at finde den. Men hvis bøgerne er arrangeret efter "indholdsrelevans", vil den bog, du leder efter, være placeret sammen med bøger om lignende emner, hvilket gør det meget hurtigere at finde. Dette er vigtigheden af vektordatabaser: De kan i høj grad forbedre effektiviteten af at finde og analysere store mængder data.
Hvordan man bruger dem
Når man bruger en vektordatabase, skal man først have et datasæt, såsom tekst, billeder eller lyd. Disse data vil blive konverteret til "vektorer" gennem "maskinlæringsmodeller". Derefter gemmes disse vektorer i vektordatabasen. Når en bruger fremsætter en forespørgsel, konverteres denne forespørgsel også til en vektor, og databasen finder hurtigt de datavektorer, der er tættest på forespørgselsvektoren, og finder dermed den information, brugeren har brug for.
Anvendelser
Vektordatabaser bruges af virksomheder i forskellige brancher, der har brug for at håndtere store mængder data. Dette inkluderer teknologivirksomheder, finansielle institutioner, sundhedsorganisationer og endda detailhandlere. Enhver organisation, der har brug for at "hurtigt finde den nødvendige information i et hav af ustrukturerede data", kan bruge vektordatabaser.
Fordele
Fordelene ved vektordatabaser ligger i deres høje effektivitet og nøjagtighed. De kan hurtigt behandle og hente store mængder komplekse data, hvilket ofte er umuligt med traditionelle databaser. Desuden er vektordatabaser også fremragende til at håndtere uklare forespørgsler, hvilket er afgørende for maskinlæring og kunstig intelligens-applikationer.
Udfordringer
De kræver store mængder beregningsressourcer, især når man håndterer meget store datasæt. Derudover kræver de højt specialiseret viden til opsætning og vedligeholdelse. Endelig er databeskyttelse og sikkerhed også en vigtig overvejelse.
Efter at have fået en grundlæggende forståelse af vektordatabaser, lad os nu med diagrammer og konkrete eksempler få en mere specifik forståelse af, hvordan vektordatabaser fungerer!
Introduktion til vektordatabaser gennem visuelle diagrammer
Vi starter med grundlæggende konceptdiagrammer for at forklare vektordatabasens funktionsprincipper og derefter udføre en konkret casestudie. Her er en beskrivelse af disse to dele:
Diagramforklaring af funktionsprincipper
- Vektorkonverteringsdiagram: Dette diagram viser, hvordan tekst-, billed- eller lyddata konverteres til vektorer.
- Vektorrumsdiagram: I et flerdimensionelt rum repræsenterer hvert punkt en vektor, og dette diagram viser, hvordan disse punkter grupperes sammen baseret på lighed. Vi kan bruge punkter i forskellige farver til at repræsentere forskellige datakategorier.
- Forespørgselsbehandlingsdiagram: Fra brugerens input af forespørgslen til at få resultatet, vil dette diagram vise hele søgeprocessen. Dette vil omfatte brugerens forespørgselsinput, konverteringsprocessen til en vektor, matchningsprocessen i databasen og de endelige lignende resultater, der returneres til brugeren.
Konkrete casestudier
Antag, at en e-handelsvirksomhed ønsker at forbedre nøjagtigheden og effektiviteten af deres "produktanbefalingssystem" med det mål, at når brugere søger efter produkter, kan de hurtigt finde og anbefale de mest relevante produkter.
Case-implementeringstrin:
- Dataindsamling: Virksomheden indsamler data fra deres produktdatabase, herunder produktbeskrivelser, billeder og kundeanmeldelser.
- Vektorkonvertering: Ved hjælp af maskinlæringsmodeller konverteres hver produkts beskrivelse og billede til vektorer.
- Oprettelse af vektordatabase: Disse vektorer gemmes i en vektordatabase, og der oprettes et hurtigt søgesystem.
- Brugerforespørgselsbehandling: Når en bruger indtaster en søgeforespørgsel, f.eks. sportssko, konverterer systemet denne forespørgsel til en vektor og søger efter de mest lignende vektorer i vektordatabasen.
- Returnering af resultater: Systemet konverterer de mest lignende produktvektorer tilbage til produktinformation og viser dem til brugeren.
Vi vil bruge Python til at beskrive disse koncepter. Lad os se på det første diagram: vektorkonverteringsdiagram.
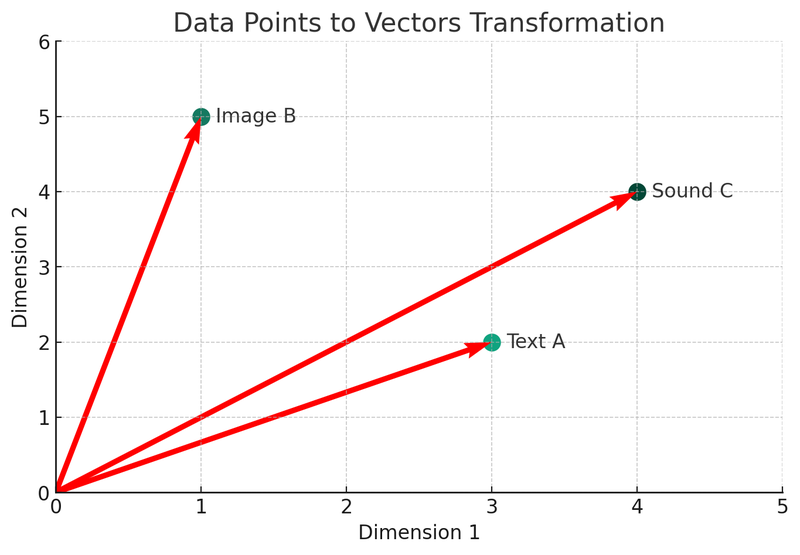
I denne illustration kan vi se tre forskellige datatyper (tekst A, billede B, lyd C) blive konverteret til vektorer i et todimensionelt rum. Hvert punkt repræsenterer en vektor, dvs. den matematiske repræsentation af de originale data. Denne proces er kernen i vektordatabasens indekserings- og søgemekanisme.
Dernæst vil vi tegne det andet diagram: vektorrumsdiagrammet, der viser, hvordan disse datapunkter (nu vektorer) grupperes i et flerdimensionelt rum baseret på lighed.
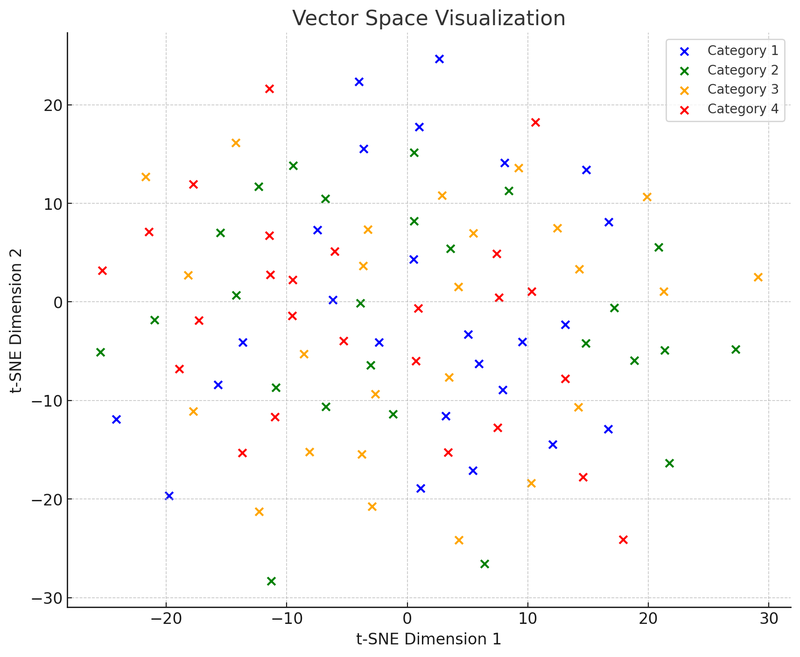
I denne visualisering af vektorrummet bruger vi t-SNE (t-distributed Stochastic Neighbor Embedding), en almindeligt anvendt dimensionreduktionsteknik, der hjælper os med at projicere højdimensionelle data til to- eller tredimensionelle rum for at lette visualiseringen. Dette diagram viser fordelingen af 100 datapunkter (oprindeligt i et 50-dimensionelt rum) efter at være reduceret til et todimensionelt rum. Antag, at disse punkter er opdelt i fire kategorier, hver kategori repræsenteret med en anden farve. Sådan visualisering hjælper med at forstå, hvordan vektordatabase fungerer: De kan gruppere lignende datapunkter baseret på den relative afstand mellem datapunkter (dvs. vektorer). Denne egenskab gør det muligt for vektordatabase hurtigt at finde "nabo"-punkter, dvs. de datapunkter, der ligner forespørgslen mest, når de søger.
For at simulere et e-handelsvirksomheds produktanbefalingssystem vil vi oprette et forenklet eksempel, der inkluderer: et sæt produktvektorer og en brugers forespørgselsvektor. Vi vil gennem en grafisk fremstilling vise fordelingen af disse produktvektorer i vektorrummet og hvordan brugerens "forespørgselsvektor" finder "de nærmeste produktvektorer" for at illustrere anvendelsen af vektordatabase i produktanbefalingssystemer.
Grafisk casestudie
Først genererer vi et sæt simulerede produktvektorer og definerer derefter en brugers forespørgselsvektor. Derefter vil vi
bruge et diagram til at vise, hvordan denne forespørgselsvektor lokaliseres i vektorrummet og finder de nærmeste produktvektorer.
Lad os starte denne proces.
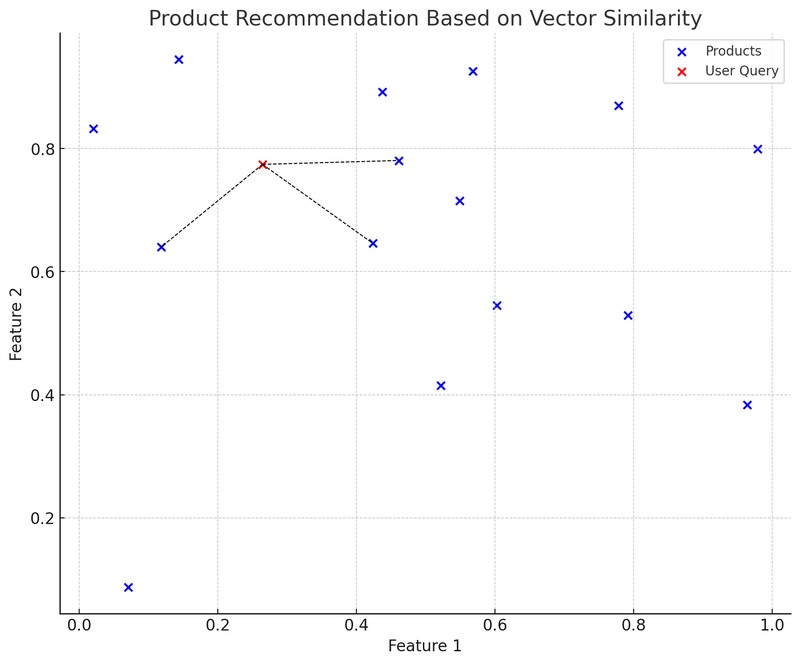
I dette diagram repræsenterer de blå prikker forskellige produkter på e-handelsplatformen, hvor hvert produkt har en todimensionel funktionsvektor. Den røde prik er en brugers forespørgsel, som også er blevet konverteret til en todimensionel vektor. Vi bruger datastrukturen K-D Tree (KDTree) til hurtigt at finde de produktvektorer, der er tættest på "brugerens forespørgsel".
I diagrammet repræsenterer forbindelsen (sort stiplet linje) fra brugerens forespørgselsvektor (rød prik) til den nærmeste produktvektor: Anbefalingssystemet vil anbefale disse produkter til brugeren baseret på ligheden mellem vektorerne. Dette er et forenklet eksempel på, hvordan vektordatabase anvendes i praksis: Brugeren fremsætter en forespørgsel, systemet konverterer forespørgslen til en vektor og finder hurtigt de mest lignende produktvektorer i vektordatabasen for at anbefale relevante produkter til brugeren.
Fordelen ved denne metode er, at anbefalingerne er hurtige og relativt præcise, da de er baseret på matematisk beregning af produktfunktioner og ikke kun nøgleords matchning. Udfordringerne inkluderer: hvordan man vælger og justerer funktionsvektorer for bedst at beskrive og repræsentere produktfunktioner, samt hvordan man håndterer "koldstart"-problemet for nye produkter eller sjældne forespørgsler.
Konklusion
I nutidens datadrevne beslutningsmiljø håndterer og henter vektordatabase store mængder flerdimensionelle data på en unik og kraftfuld måde, hvilket gør dem til det ideelle valg for kunstig intelligens og maskinlæringsapplikationer. Fra at forbedre relevansen af søgeresultater til at fremme personlige produktanbefalinger bliver vektordatabase hurtigt et værdifuldt værktøj for dataingeniører og teknologiske innovatører i forskellige brancher. Gennem Appar Technologies' illustrationer og casestudier håber vi at kunne give dig en klar forståelse af, hvordan vektordatabase fungerer, og hvorfor de kan levere så hurtige og præcise resultater.
Vektordatabase viser, hvor kraftfulde værktøjer og applikationer kan skabes, når folk forstår og udnytter data på nye måder. Med den fortsatte udvikling af teknologi kan vi forvente, at vektordatabase vil spille en endnu mere afgørende rolle i fremtidens databehandling og analysearbejde.
Hvis du er interesseret i, hvordan generativ AI kan skabe artikler af høj kvalitet, integrere store sprogmodeller i produkter eller interne processer, kan du kontakte generativ AI-eksperter hos Appar Technologies, hello@appar.com.tw for at booke en konsultation.