Mikä on vektoripohjainen tietokanta?
By Sean Chen, 10. marraskuuta 2023

Tämä artikkelisarja on osa 'Anna tekoälyn selittää tekoälyä' -sarjaa, jonka koko sisältö on kirjoitettu GPT-4:n ja muiden suurten kielimallien avulla ihmisen valvonnassa. Sarja tarjoaa syvällistä tietoa, jotta eri taustoista tulevat ammattilaiset voivat helposti täydentää AI-tietämystään. Alussa selitetään kyseisen tiedon merkitys liiketoiminnalle, ja lopussa käsitellään syvällisempiä teknisiä yksityiskohtia.
Kun liiketoiminta kohtaa suurten tietomäärien aikakauden, vektoripohjaiset tietokannat ovat kuin majakka jäsentämättömän datan meressä, valaisten nopean tiedonhaun polkua. Tämä artikkeli vie sinut syvemmälle ymmärtämään, miten tämä teknologia toimii ja mitä merkitystä sillä on yritysmaailmassa.
Vektoripohjaisten tietokantojen periaatteet ja olemus
Vektoripohjaiset tietokannat käyttävät matematiikan 'vektoreita' tiedon tallentamiseen. Otetaanpa esimerkki arjesta: Kuvittele, että huoneessasi on paljon erivärisiä palloja, joista jokainen edustaa tiettyä tietoa. Nyt haluat sijoittaa pallot kirjahyllyyn niin, että niiden sijainnit heijastavat kunkin pallon värin ominaisuuksia. Päätät käyttää 'värikartta'-muistikirjaa auttamaan sinua löytämään kullekin pallolle oikean paikan. Tässä muistikirjassa samanväriset pallot sijoitetaan lähelle toisiaan, kun taas eriväriset pallot sijoitetaan kauemmas toisistaan.
Vektoripohjainen tietokanta toimii samalla periaatteella: se muuntaa erilaiset tiedot (kuten teksti, kuvat tai ääni) matemaattisiksi vektoreiksi (kuten mainitut pallot). Näillä vektoreilla on oma sijaintinsa moniulotteisessa tilassa, aivan kuten pallot kirjahyllyssä. Kun haluat nopeasti löytää jonkin tiedon, joka on samankaltainen kuin jokin toinen tieto, vektoripohjainen tietokanta auttaa sinua löytämään lähimmän vektorin tässä moniulotteisessa tilassa (aivan kuten löytää väriltään lähimmän pallon).
Yksinkertaisesti sanottuna, se on matemaattinen tapa abstrahoida tietojen ominaisuudet pisteiksi tilassa ja laskea näiden pisteiden välisiä etäisyyksiä löytääkseen nopeasti samankaltaiset tiedot.
Miksi se on tärkeää
Kuvittele, että olet suuressa kirjastossa etsimässä tiettyä kirjaa. Jos kaikki kirjat on järjestetty vain tekijän tai otsikon mukaan, saatat joutua käyttämään paljon aikaa etsimiseen. Mutta jos kirjat on järjestetty 'sisällön samankaltaisuuden' mukaan, haluamasi kirja löytyy nopeasti samankaltaisten kirjojen joukosta. Tämä on vektoripohjaisten tietokantojen merkitys: ne voivat huomattavasti parantaa suurten tietomäärien hakua ja analysointia.
Kuinka käyttää
Kun käytät vektoripohjaista tietokantaa, tarvitset ensin tietojoukon, kuten tekstiä, kuvia tai ääntä. Nämä tiedot muunnetaan 'vektoreiksi' koneoppimismallin avulla. Sitten nämä vektorit tallennetaan vektoripohjaiseen tietokantaan. Kun käyttäjä tekee haun, tämä haku muunnetaan myös vektoriksi, ja tietokanta löytää nopeasti tiedot, joiden vektorit ovat lähimpänä tätä hakua.
Sovellukset
Vektoripohjaisia tietokantoja käyttävät yritykset, jotka käsittelevät suuria tietomääriä eri aloilla. Näitä ovat esimerkiksi teknologiayritykset, rahoituslaitokset, terveydenhuollon organisaatiot ja jopa vähittäiskauppiaat. Kaikki organisaatiot, jotka tarvitsevat 'nopeasti löytää tarvitsemaansa tietoa jäsentämättömän datan merestä', voivat käyttää vektoripohjaisia tietokantoja.
Edut
Vektoripohjaisten tietokantojen etuna on niiden tehokkuus ja tarkkuus. Ne voivat nopeasti käsitellä ja hakea suuria määriä monimutkaista dataa, mikä ei usein ole mahdollista perinteisillä tietokannoilla. Lisäksi vektoripohjaiset tietokannat ovat erinomaisia epätarkkojen hakujen käsittelyssä, mikä on erittäin tärkeää koneoppimis- ja tekoälysovelluksille.
Haasteet
Ne vaativat paljon laskentatehoa, erityisesti suurten tietojoukkojen käsittelyssä. Lisäksi niiden asettaminen ja ylläpito vaatii korkeasti erikoistunutta tietämystä. Lopuksi, tietojen yksityisyys ja turvallisuus ovat myös tärkeitä huomioon otettavia seikkoja.
Kun olet saanut perustiedot vektoripohjaisista tietokannoista, seuraavaksi tarkastelemme kaavioita ja käytännön esimerkkejä, jotta voimme konkreettisemmin ymmärtää, miten vektoripohjaiset tietokannat toimivat!
Vektoripohjaisten tietokantojen esittely visuaalisten kaavioiden avulla
Aloitamme peruskäsitteiden kaaviolla selittääksemme vektoripohjaisten tietokantojen toimintaperiaatetta ja jatkamme konkreettisella tapausanalyysillä. Tässä on kuvaus näistä kahdesta osasta:
Toimintaperiaatteen kaavioselitys
- Vektorimuunnoskaavio: Tämä kaavio näyttää, miten teksti-, kuva- tai äänitiedot muunnetaan vektoreiksi.
- Vektoritilakaavio: Moniulotteisessa tilassa jokainen piste edustaa vektoria, ja tämä kaavio näyttää, miten nämä pisteet ryhmitellään samankaltaisuuden perusteella. Voimme käyttää eri värisiä pisteitä edustamaan eri tietoluokkia.
- Hakuprosessin kaavio: Käyttäjän syötteestä tulokseen, tämä prosessikaavio näyttää koko hakuprosessin. Tämä sisältää käyttäjän haun syötteen, muuntamisen vektoriksi, vektorin sovittamisen tietokannassa ja lopulta käyttäjälle palautettavat samankaltaiset tulokset.
Konkreettinen tapausanalyysi
Kuvitellaan, että verkkokauppayritys haluaa parantaa 'tuotesuositusjärjestelmänsä' tarkkuutta ja tehokkuutta. Tavoitteena on, että kun käyttäjä hakee tuotetta, järjestelmä löytää ja suosittelee nopeasti relevantteja tuotteita.
Tapausanalyysin vaiheet:
- Tietojen keruu: Yritys kerää tietoja tuotekannastaan, mukaan lukien tuotekuvaukset, kuvat ja asiakasarvostelut.
- Vektorimuunnos: Koneoppimismallin avulla jokaisen tuotteen kuvaus ja kuva muunnetaan vektoriksi.
- Vektoripohjaisen tietokannan luominen: Nämä vektorit tallennetaan vektoripohjaiseen tietokantaan, ja luodaan nopea hakujärjestelmä.
- Käyttäjän hakuprosessi: Kun käyttäjä syöttää hakusanan, kuten 'lenkkarit', järjestelmä muuntaa tämän haun vektoriksi ja etsii vektoripohjaisesta tietokannasta lähimmät vektorit.
- Tulosten palautus: Järjestelmä muuntaa samankaltaisimmat tuotevektorit takaisin tuotetiedoiksi ja näyttää ne käyttäjälle.
Käytämme Pythonia näiden käsitteiden kuvaamiseen. Katsotaanpa ensimmäistä kaaviota: vektorimuunnoskaavio.
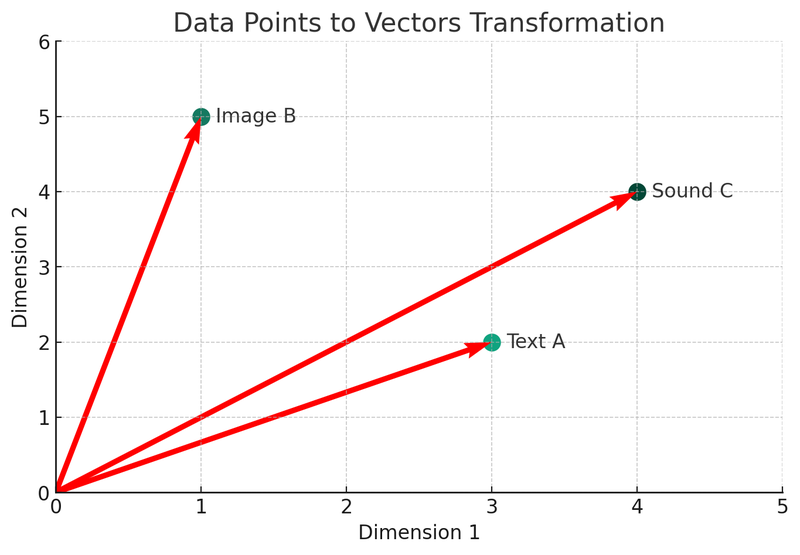
Tässä kuvassa näemme, miten kolme erilaista tietotyyppiä (teksti A, kuva B, ääni C) muunnetaan vektoreiksi kaksiulotteisessa tilassa. Jokainen piste edustaa vektoria, eli alkuperäisen tiedon matemaattista esitystapaa. Tämä prosessi on vektoripohjaisten tietokantojen indeksointi- ja hakumekanismin ydin.
Seuraavaksi piirrämme toisen kaavion: vektoritilakaavio, joka näyttää, miten nämä tietopisteet (nyt vektorit) ryhmitellään samankaltaisuuden perusteella moniulotteisessa tilassa.
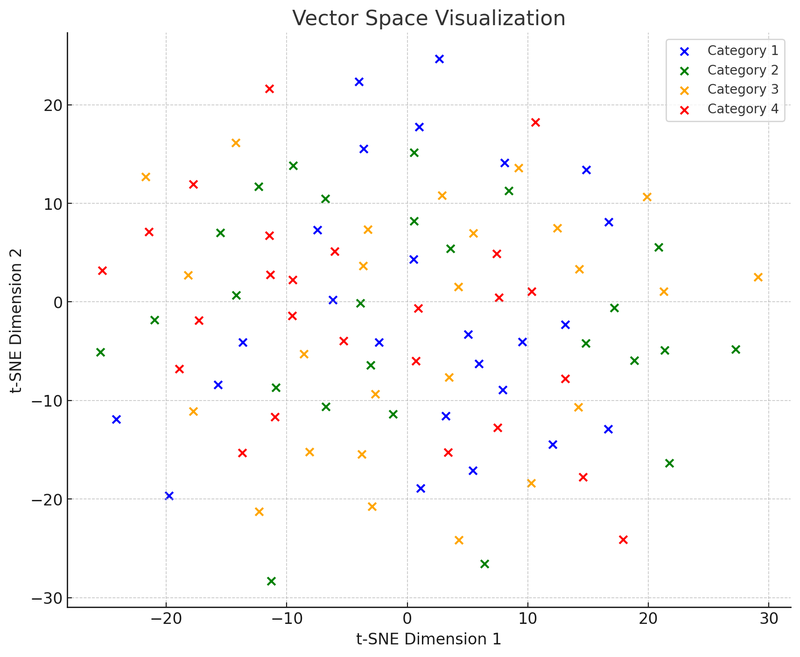
Tässä vektoritilan visualisointikuvassa käytämme t-SNE:tä (t-distributed Stochastic Neighbor Embedding), joka on yleisesti käytetty dimensioiden vähennystekniikka. Se auttaa meitä projisoimaan korkean ulottuvuuden tiedot kaksi- tai kolmiulotteiseen tilaan visualisointia varten. Tämä kaavio näyttää, miten 100 tietopistettä (alun perin 50-ulotteisessa tilassa) jakautuvat kaksiulotteisessa tilassa. Oletetaan, että nämä pisteet on jaettu neljään luokkaan, ja jokainen luokka on merkitty eri värillä. Tällainen visualisointi auttaa ymmärtämään, miten vektoripohjaiset tietokannat toimivat: ne voivat ryhmitellä samankaltaiset tietopisteet (eli vektorit) yhteen niiden suhteellisen etäisyyden perusteella. Tämä ominaisuus mahdollistaa sen, että vektoripohjaiset tietokannat voivat nopeasti löytää 'naapuripisteet', eli ne tietopisteet, jotka ovat eniten samankaltaisia haun kanssa.
Simuloidaksemme verkkokauppayrityksen tuotesuositusjärjestelmää, luomme yksinkertaistetun esimerkin, joka sisältää: joukon tuotevektoreita ja käyttäjän hakukyselyn vektorin. Näytämme visuaalisesti, miten nämä tuotevektorit jakautuvat vektoritilassa ja miten käyttäjän 'hakukyselyvektori' löytää 'lähimmän tuotevektorin', selittääksemme vektoripohjaisten tietokantojen soveltamista tuotesuositusjärjestelmissä.
Visuaalinen tapausanalyysi
Ensinnäkin, luomme joukon simuloituja tuotevektoreita ja määrittelemme käyttäjän hakukyselyvektorin. Sitten käytämme kaaviota näyttämään, miten tämä hakukyselyvektori paikantaa itsensä vektoritilassa ja löytää lähimmät tuotevektorit.
Aloitetaan tämä prosessi.
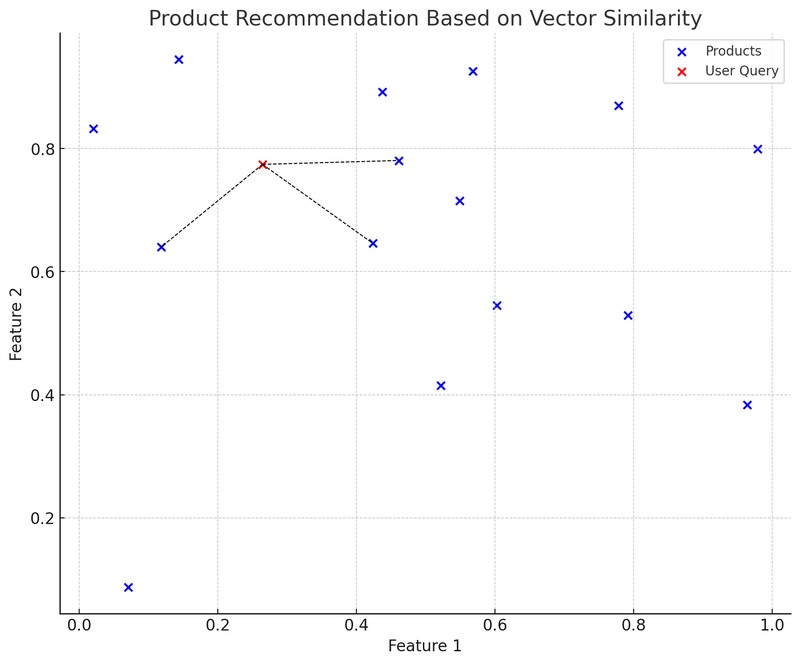
Tässä kaaviossa siniset pisteet edustavat verkkokauppa-alustan tuotteita, joista jokaisella on kaksiulotteinen ominaisuusvektori. Punainen piste on käyttäjän hakukysely, joka on myös muunnettu kaksiulotteiseksi vektoriksi. Käytämme K-D puuta (KDTree) -tietorakennetta löytääksemme nopeasti 'käyttäjän hakukyselyä lähimmän tuotevektorin'.
Kaaviossa käyttäjän hakukyselyvektorista (punainen piste) lähimpään tuotevektoriin kulkeva viiva (musta katkoviiva) osoittaa, että suositusjärjestelmä suosittelee käyttäjälle tuotteita vektorien samankaltaisuuden perusteella. Tämä on yksinkertaistettu esimerkki vektoripohjaisten tietokantojen käytöstä: käyttäjä tekee haun, järjestelmä muuntaa haun vektoriksi ja löytää vektoripohjaisesta tietokannasta nopeasti samankaltaisimmat tuotevektorit, jolloin se voi suositella käyttäjälle relevantteja tuotteita.
Tämän menetelmän etuna on, että suositukset ovat nopeita ja suhteellisen tarkkoja, koska ne perustuvat tuotteiden ominaisuuksien matemaattiseen laskentaan, eivätkä pelkästään avainsanojen sovittamiseen. Haasteita ovat muun muassa: miten valita ja säätää ominaisuusvektoreita, jotta ne parhaiten kuvaavat ja edustavat tuotteiden ominaisuuksia, sekä miten käsitellä uusia tuotteita tai harvinaisia hakuja 'kylmäkäynnistys' (Cold Start) -ongelman yhteydessä.
Johtopäätös
Nykyisessä dataohjatussa päätöksentekoympäristössä vektoripohjaiset tietokannat käsittelevät ja hakevat suuria moniulotteisia tietoja ainutlaatuisella ja tehokkaalla tavalla, mikä tekee niistä ihanteellisen valinnan tekoäly- ja koneoppimissovelluksille. Ne parantavat hakutulosten relevanssia ja edistävät henkilökohtaisten tuotesuositusten kehittämistä. Vektoripohjaiset tietokannat ovat nopeasti tulossa arvokkaaksi työkaluksi eri alojen data-insinööreille ja teknologiainnovoijille. Toivomme, että Appar Technologiesin kaaviot ja tapausanalyysit auttavat sinua ymmärtämään, miten vektoripohjaiset tietokannat toimivat ja miksi ne voivat tarjota niin nopeita ja tarkkoja tuloksia.
Vektoripohjaiset tietokannat osoittavat, kuinka voimakkaita työkaluja ja sovelluksia voidaan luoda, kun ihmiset ymmärtävät ja hyödyntävät tietoa uudella tavalla. Teknologian kehittyessä voimme odottaa, että vektoripohjaiset tietokannat tulevat olemaan entistä tärkeämmässä roolissa tulevaisuuden tietojenkäsittely- ja analyysitehtävissä.
Jos olet kiinnostunut siitä, miten generatiivinen AI voi tuottaa korkealaatuisia artikkeleita, integroida suuria kielimalleja tuotteisiin tai yrityksen sisäisiin prosesseihin, voit ottaa yhteyttä generatiivisen AI:n asiantuntijaan Appar Technologies, hello@appar.com.tw varataksesi konsultaation.