Wat is een vector database?
By Sean Chen, 10 november 2023

Deze serie artikelen is "Laat AI AI uitleggen", volledig geschreven door grote taalmodellen zoals GPT-4 onder menselijk toezicht. Deze serie biedt op een toegankelijke manier AI-gerelateerde kennis aan mensen met verschillende achtergronden. Het eerste deel legt de zakelijke betekenis van het kennispunt uit, terwijl het tweede deel dieper ingaat op technische details.
Wanneer bedrijven worden geconfronteerd met het tijdperk van big data, wordt de vector database een baken in de wereld van ongestructureerde data, dat de weg naar snelle informatieopvraging verlicht. Dit artikel neemt u mee in de werking van deze technologie en de betekenis en impact ervan op het bedrijfsleven.
De principes en essentie van vector databases
Vector databases gebruiken het wiskundige concept van "vectoren" om informatie op te slaan. Laten we een voorbeeld uit het dagelijks leven gebruiken om dit uit te leggen: stel dat uw kamer vol ligt met gekleurde ballen, waarbij elke bal een soort data vertegenwoordigt. Nu wilt u de ballen op specifieke plaatsen in een boekenkast zetten, en deze plaatsen moeten de kleurkenmerken van elke bal weerspiegelen. U besluit een "kleurenkaart" notitieboek te gebruiken om u te helpen de locatie van elke bal te vinden. In dit notitieboek worden ballen met vergelijkbare kleuren dichter bij elkaar geplaatst, terwijl ballen met verschillende kleuren verder uit elkaar worden geplaatst.
Een vector database werkt volgens hetzelfde principe: het zet verschillende soorten data (zoals tekst, afbeeldingen of geluid) om in wiskundige vectoren (zoals de eerder genoemde ballen). Deze vectoren hebben hun eigen positie in een multidimensionale ruimte, net als de ballen in de boekenkast. Wanneer u snel data wilt vinden die het meest lijkt op een bepaalde data, helpt de vector database u om in deze multidimensionale ruimte de vectoren te vinden die het dichtst bij elkaar liggen (net zoals het vinden van de ballen met de meest vergelijkbare kleuren).
Kortom, door middel van wiskundige methoden worden de kenmerken van data geabstraheerd tot punten in de ruimte, en door de afstand tussen deze punten te berekenen, kan snel vergelijkbare data worden gevonden.
Waarom het belangrijk is
Stel je voor dat je in een grote bibliotheek op zoek bent naar een specifiek boek. Als elk boek alleen op auteur of titel is gerangschikt, zou je veel tijd kunnen besteden aan het zoeken. Maar als boeken zijn gerangschikt op "inhoudsrelevantie", dan zou het boek dat je zoekt samen met boeken over vergelijkbare onderwerpen worden geplaatst, waardoor het veel sneller te vinden is. Dit is de belangrijkheid van vector databases: ze kunnen de efficiëntie van het zoeken en analyseren van grote hoeveelheden data enorm verbeteren.
Hoe te gebruiken
Bij het gebruik van een vector database begint u met een dataset, zoals tekst, afbeeldingen of geluid. Deze data worden door een "machine learning model" omgezet in "vectoren". Vervolgens worden deze vectoren opgeslagen in de vector database. Wanneer een gebruiker een query indient, wordt deze query ook omgezet in een vector, en de database vindt snel de data vectoren die het dichtst bij deze query vector liggen, waardoor de gebruiker de benodigde informatie vindt.
Toepassingen
Vector databases worden gebruikt door bedrijven in verschillende sectoren die grote hoeveelheden data moeten verwerken. Dit omvat technologiebedrijven, financiële instellingen, gezondheidszorginstellingen en zelfs detailhandelaren. Elke organisatie die "snel de benodigde informatie uit een zee van moeilijk te structureren data" moet vinden, kan een vector database gebruiken.
Voordelen
De voordelen van vector databases liggen in hun hoge efficiëntie en nauwkeurigheid. Ze kunnen snel grote hoeveelheden complexe data verwerken en opvragen, wat vaak niet mogelijk is met traditionele databases. Bovendien zijn vector databases uitstekend in het verwerken van vage queries, wat cruciaal is voor machine learning en AI-toepassingen.
Uitdagingen
Ze vereisen veel rekenkracht, vooral bij het verwerken van zeer grote datasets. Daarnaast is er gespecialiseerde kennis nodig om ze op te zetten en te onderhouden. Tot slot zijn de privacy en beveiliging van data ook belangrijke overwegingen.
Na een basisbegrip van vector databases te hebben gekregen, laten we verder gaan met grafieken en praktijkvoorbeelden om een concreter begrip van de werking van vector databases te krijgen!
Een introductie tot vector databases via visuele grafieken
We beginnen met een basisconceptdiagram om de werking van vector databases uit te leggen, gevolgd door een concrete casestudy. Hieronder volgt een beschrijving van deze twee delen:
Diagramuitleg van de werking
- Vector conversiediagram: Dit diagram laat zien hoe tekst-, beeld- of geluidsdata worden omgezet in vectoren.
- Vector ruimtediagram: In een multidimensionale ruimte vertegenwoordigt elk punt een vector. Dit diagram laat zien hoe deze punten op basis van gelijkenis worden gegroepeerd. We kunnen verschillende kleuren gebruiken om verschillende datacategorieën weer te geven.
- Queryverwerkingsstroomdiagram: Van het invoeren van een gebruikersquery tot het verkrijgen van resultaten, dit stroomdiagram toont het hele opvraagproces. Dit omvat de invoer van de gebruikersquery, het omzetten in een vector, het matchen van de vector in de database en het uiteindelijk teruggeven van vergelijkbare resultaten aan de gebruiker.
Concrete casestudy
Stel dat er een e-commercebedrijf is dat de nauwkeurigheid en efficiëntie van zijn "productaanbevelingssysteem" wil verbeteren, met als doel dat gebruikers snel de meest relevante producten kunnen vinden en aanbevelen wanneer ze naar producten zoeken.
Stappen in de casestudy:
- Data verzamelen: Het bedrijf verzamelt data uit zijn productdatabase, inclusief productbeschrijvingen, afbeeldingen en klantbeoordelingen.
- Vector conversie: Met behulp van machine learning modellen worden de beschrijvingen en afbeeldingen van elk product omgezet in vectoren.
- Vector database opzetten: Deze vectoren worden opgeslagen in een vector database en er wordt een snel opvraagsysteem opgezet.
- Gebruikersqueryverwerking: Wanneer een gebruiker een zoekwoordquery invoert, bijvoorbeeld: sportschoenen, zet het systeem deze query om in een vector en zoekt het in de vector database naar de meest vergelijkbare vectoren.
- Resultaten teruggeven: Het systeem zet de productvectoren met de hoogste gelijkenis om in productinformatie en toont deze aan de gebruiker.
We zullen Python gebruiken om deze concepten te illustreren. Laten we naar het eerste diagram kijken: het vector conversiediagram.
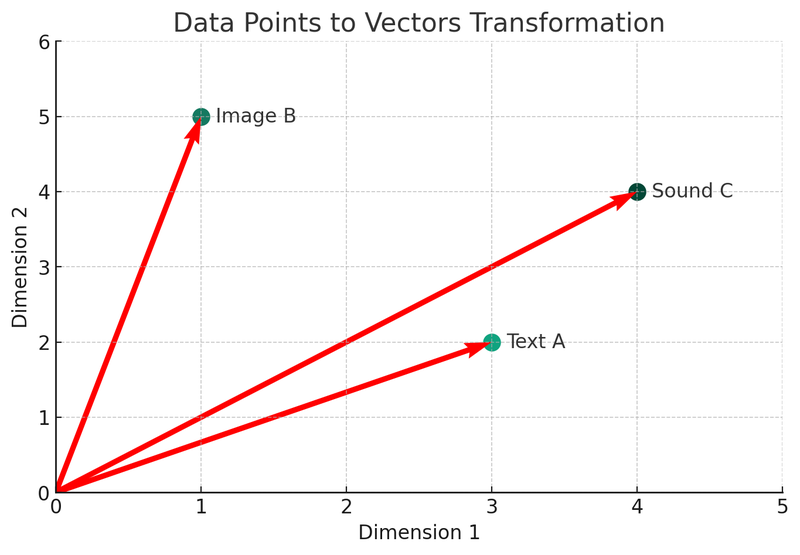
In deze illustratie zien we drie verschillende datatypes (tekst A, afbeelding B, geluid C) die worden omgezet in vectoren in een tweedimensionale ruimte. Elk punt vertegenwoordigt een vector, oftewel de wiskundige representatie van de oorspronkelijke data. Dit proces is de kern van het indexerings- en opvraagmechanisme van vector databases.
Vervolgens zullen we het tweede diagram tekenen: het vector ruimtediagram, dat laat zien hoe deze datapunten (nu vectoren) op basis van gelijkenis worden gegroepeerd in een multidimensionale ruimte.
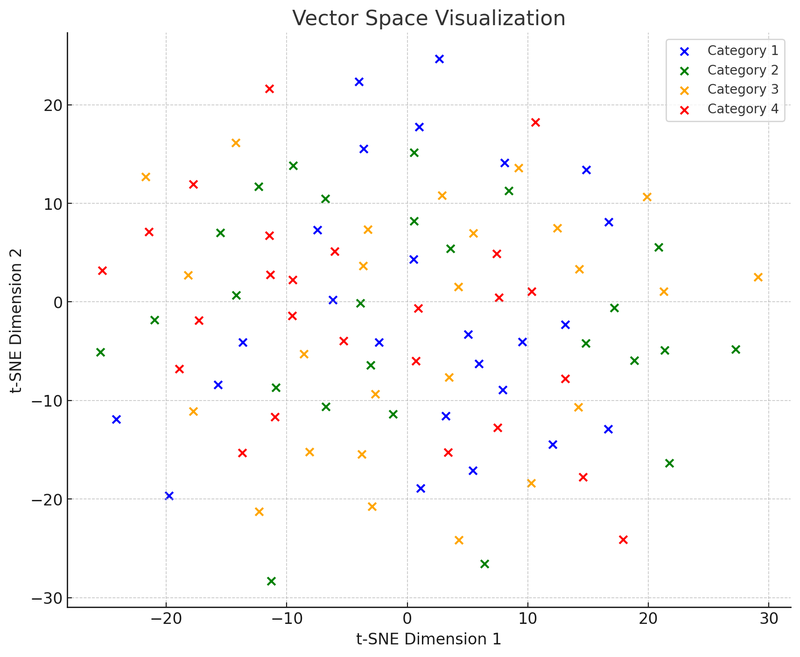
In deze visualisatie van de vectorruimte hebben we gebruik gemaakt van t-SNE (t-distributed Stochastic Neighbor Embedding), een veelgebruikte dimensiereductietechniek die ons helpt om hoge-dimensionale data te projecteren naar een twee- of driedimensionale ruimte voor visualisatie. Dit diagram toont de verdeling van 100 datapunten (oorspronkelijk in een 50-dimensionale ruimte) nadat ze zijn gereduceerd tot een tweedimensionale ruimte. Stel dat deze punten in vier categorieën zijn verdeeld, waarbij elke categorie met een andere kleur wordt weergegeven. Deze visualisatie helpt te begrijpen hoe vector databases werken: ze kunnen op basis van de relatieve afstand tussen datapunten (oftewel vectoren) vergelijkbare datapunten bij elkaar groeperen. Deze eigenschap maakt het mogelijk voor vector databases om tijdens het opvragen snel "buren" te vinden, oftewel die datapunten die het meest lijken op de query.
Om het productaanbevelingssysteem van een e-commercebedrijf te simuleren, zullen we een vereenvoudigd voorbeeld opzetten met: een set productvectoren en een gebruikersqueryvector. We zullen visueel laten zien hoe deze productvectoren zijn verdeeld in de vectorruimte en hoe de "queryvector" van de gebruiker de "dichtstbijzijnde productvector" vindt, om de toepassing van vector databases in productaanbevelingssystemen te illustreren.
Visuele casestudy
Ten eerste genereren we een set gesimuleerde productvectoren en definiëren we een gebruikersqueryvector. Vervolgens zullen we
met een diagram laten zien hoe deze queryvector zich positioneert in de vectorruimte en de dichtstbijzijnde productvector vindt.
Laten we dit proces starten.
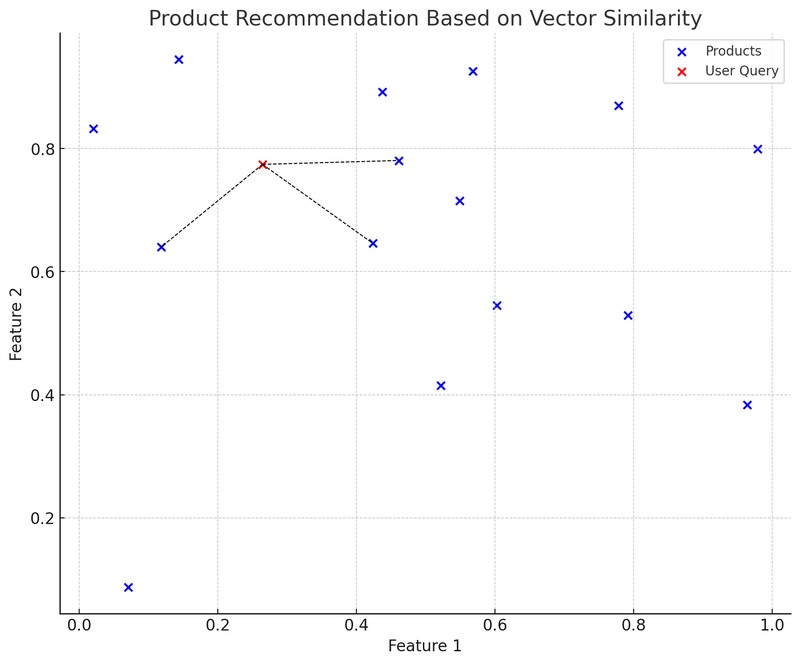
In dit diagram vertegenwoordigen de blauwe punten de verschillende producten op het e-commerce platform, waarbij elk product een tweedimensionale kenmerkvector heeft. Het rode punt is een gebruikersquery, die ook is omgezet in een tweedimensionale vector. We hebben de K-D boom (KDTree) datastructuur gebruikt om snel de "productvector die het dichtst bij de gebruikersquery ligt" te vinden.
In het diagram geeft de lijn (zwarte stippellijn) van de gebruikersqueryvector (rood punt) naar de dichtstbijzijnde productvector aan dat het aanbevelingssysteem op basis van de gelijkenis tussen vectoren deze producten aan de gebruiker zal aanbevelen. Dit is een vereenvoudigd voorbeeld van hoe vector databases in de praktijk worden toegepast: een gebruiker dient een query in, het systeem zet de query om in een vector en vindt snel de meest vergelijkbare productvector in de vector database, om zo relevante producten aan de gebruiker aan te bevelen.
Het voordeel van deze methode is dat de aanbevelingen snel en relatief nauwkeurig zijn, omdat ze zijn gebaseerd op wiskundige berekeningen van productkenmerken, en niet alleen op sleutelwoordmatching. Uitdagingen omvatten: hoe de kenmerkvectoren te kiezen en aan te passen om de productkenmerken het beste te beschrijven en weer te geven, en hoe om te gaan met het "cold start" probleem van nieuwe producten of minder vaak voorkomende queries.
Conclusie
In de huidige data-gedreven zakelijke omgeving bieden vector databases een unieke en krachtige manier om grote hoeveelheden multidimensionale data te verwerken en op te vragen, waardoor ze een ideale keuze zijn voor AI- en machine learning-toepassingen. Van het verbeteren van de relevantie van zoekresultaten tot het stimuleren van gepersonaliseerde productaanbevelingen, vector databases worden snel een waardevol hulpmiddel voor data-ingenieurs en technologische innovators in verschillende sectoren. Met de illustraties en casestudy's van Appar Technologies hopen we duidelijk te maken hoe vector databases werken en waarom ze zulke snelle en nauwkeurige resultaten kunnen bieden.
Vector databases tonen aan hoe krachtige tools en toepassingen kunnen worden gecreëerd wanneer mensen data op nieuwe manieren begrijpen en gebruiken. Naarmate de technologie zich blijft ontwikkelen, kunnen we verwachten dat vector databases een nog crucialere rol zullen spelen in toekomstige data verwerking en analyse.
Als u geïnteresseerd bent in hoe generatieve AI hoogwaardige artikelen kan produceren, grote taalmodellen kan integreren in producten of interne bedrijfsprocessen, kunt u contact opnemen met de generatieve AI-experts van Appar Technologies, hello@appar.com.tw voor een consultatie.