Cơ sở dữ liệu vector là gì?
By Sean Chen, Ngày 10 tháng 11 năm 2023

Loạt bài viết này là "Để AI giải thích AI", toàn bộ nội dung được viết bởi các mô hình ngôn ngữ lớn như GPT-4 dưới sự giám sát của con người. Loạt bài này nhằm cung cấp kiến thức về AI một cách dễ hiểu cho những người làm việc từ các nền tảng khác nhau. Phần đầu giải thích ý nghĩa của kiến thức này đối với khía cạnh kinh doanh, phần sau giải thích chi tiết kỹ thuật sâu hơn.
Khi doanh nghiệp đối mặt với sự xuất hiện của thời đại dữ liệu lớn, cơ sở dữ liệu vector trở thành ngọn đèn sáng trong dữ liệu phi cấu trúc, chiếu sáng con đường tìm kiếm thông tin nhanh chóng. Bài viết này sẽ giúp bạn hiểu sâu hơn về cách công nghệ này hoạt động và ý nghĩa cũng như ảnh hưởng của nó đối với giới doanh nghiệp.
Nguyên lý và bản chất của cơ sở dữ liệu vector
Cơ sở dữ liệu vector sử dụng "vector" trong toán học để lưu trữ thông tin. Hãy lấy một ví dụ trong cuộc sống để giải thích: Giả sử trong phòng bạn có nhiều quả bóng nhỏ với các màu sắc khác nhau, mỗi quả bóng đại diện cho một loại dữ liệu. Bây giờ, bạn muốn đặt các quả bóng lên kệ sách ở vị trí cụ thể, và những vị trí này phải phản ánh đặc điểm màu sắc của mỗi quả bóng. Vì vậy, bạn quyết định sử dụng một cuốn "bản đồ màu sắc" để giúp bạn tìm vị trí của mỗi quả bóng. Trên cuốn sổ này, các quả bóng có màu sắc tương tự sẽ được đặt gần nhau hơn; còn những màu khác nhau sẽ được đặt xa hơn.
Cơ sở dữ liệu vector hoạt động theo nguyên lý tương tự, nó chuyển đổi các loại dữ liệu khác nhau (như văn bản, hình ảnh hoặc âm thanh) thành các vector toán học (giống như các quả bóng đã đề cập). Những vector này có vị trí riêng trong không gian đa chiều, giống như các quả bóng trên kệ sách. Khi bạn muốn nhanh chóng tìm thấy dữ liệu tương tự nhất với một dữ liệu nào đó, cơ sở dữ liệu vector sẽ giúp bạn tìm ra vector gần nhất trong không gian đa chiều này (giống như tìm ra quả bóng có màu sắc gần nhất).
Nói một cách đơn giản, đó là thông qua phương pháp toán học, trừu tượng hóa đặc điểm của dữ liệu thành các điểm trong không gian, sau đó tính toán khoảng cách giữa các điểm này để nhanh chóng tìm ra dữ liệu tương tự.
Tại sao quan trọng
Hãy tưởng tượng bạn đang tìm kiếm một cuốn sách cụ thể trong một thư viện lớn, nếu mỗi cuốn sách chỉ được sắp xếp theo tác giả hoặc tiêu đề, bạn có thể mất rất nhiều thời gian để tìm kiếm. Nhưng nếu sách được sắp xếp theo "mức độ liên quan của nội dung", thì cuốn sách bạn muốn sẽ được đặt cùng với các cuốn sách có chủ đề tương tự, giúp bạn tìm kiếm nhanh hơn nhiều. Đây chính là tầm quan trọng của cơ sở dữ liệu vector: chúng có thể cải thiện đáng kể hiệu quả tìm kiếm và phân tích một lượng lớn dữ liệu.
Cách sử dụng
Khi sử dụng cơ sở dữ liệu vector, trước tiên bạn cần có một tập dữ liệu, chẳng hạn như văn bản, hình ảnh hoặc âm thanh. Những dữ liệu này sẽ được chuyển đổi thành "vector" thông qua "mô hình học máy". Sau đó, các vector này được lưu trữ trong cơ sở dữ liệu vector. Khi người dùng đưa ra truy vấn, truy vấn đó cũng được chuyển đổi thành vector, cơ sở dữ liệu sẽ nhanh chóng tìm ra vector dữ liệu gần nhất với vector truy vấn này, từ đó tìm thấy thông tin mà người dùng cần.
Ứng dụng
Cơ sở dữ liệu vector được sử dụng bởi các công ty trong nhiều ngành công nghiệp cần xử lý một lượng lớn dữ liệu. Điều này bao gồm các công ty công nghệ, tổ chức tài chính, cơ sở y tế, thậm chí là nhà bán lẻ. Bất kỳ tổ chức nào cần "tìm kiếm nhanh chóng thông tin cần thiết từ biển dữ liệu khó cấu trúc" đều có thể sử dụng cơ sở dữ liệu vector.
Ưu điểm
Ưu điểm của cơ sở dữ liệu vector là hiệu quả cao và độ chính xác. Nó có thể xử lý và truy xuất nhanh chóng một lượng lớn dữ liệu phức tạp, điều này thường không thể thực hiện được với cơ sở dữ liệu truyền thống. Ngoài ra, cơ sở dữ liệu vector cũng rất xuất sắc trong việc xử lý các truy vấn mơ hồ, điều này rất quan trọng đối với ứng dụng học máy và trí tuệ nhân tạo.
Thách thức
Cần một lượng lớn tài nguyên tính toán, đặc biệt là khi xử lý các tập dữ liệu rất lớn. Thứ hai, chúng cần kiến thức chuyên môn cao để thiết lập và duy trì. Cuối cùng, quyền riêng tư và bảo mật dữ liệu cũng là một điểm cần cân nhắc quan trọng.
Sau khi có hiểu biết cơ bản về cơ sở dữ liệu vector, hãy cùng chúng tôi tìm hiểu sâu hơn về cách hoạt động của cơ sở dữ liệu vector thông qua biểu đồ và các trường hợp thực tế!
Giới thiệu cơ sở dữ liệu vector qua biểu đồ trực quan
Chúng ta bắt đầu từ biểu đồ khái niệm cơ bản để giải thích nguyên lý hoạt động của cơ sở dữ liệu vector, sau đó tiến hành phân tích một trường hợp cụ thể. Dưới đây là mô tả về hai phần này:
Giải thích nguyên lý hoạt động qua biểu đồ
- Biểu đồ chuyển đổi vector: Biểu đồ này cho thấy cách chuyển đổi dữ liệu văn bản, hình ảnh hoặc âm thanh thành vector.
- Biểu đồ không gian vector: Trong không gian đa chiều, mỗi điểm đại diện cho một vector, biểu đồ này sẽ cho thấy các điểm này được tập hợp lại với nhau như thế nào dựa trên độ tương đồng. Chúng ta có thể sử dụng các điểm màu khác nhau để biểu thị các loại dữ liệu khác nhau.
- Biểu đồ quy trình xử lý truy vấn: Từ khi người dùng nhập truy vấn đến khi nhận được kết quả, biểu đồ quy trình này sẽ cho thấy toàn bộ quá trình truy xuất. Điều này sẽ bao gồm đầu vào truy vấn của người dùng, quá trình chuyển đổi thành vector, quá trình đối sánh vector trong cơ sở dữ liệu, và kết quả tương tự cuối cùng được trả về cho người dùng.
Phân tích trường hợp cụ thể
Giả sử có một công ty thương mại điện tử muốn cải thiện độ chính xác và hiệu quả của "hệ thống gợi ý sản phẩm" của mình, mục tiêu là khi người dùng tìm kiếm sản phẩm, có thể nhanh chóng tìm thấy và gợi ý sản phẩm liên quan nhất.
Các bước thực hiện trường hợp:
- Thu thập dữ liệu: Công ty thu thập dữ liệu từ cơ sở dữ liệu sản phẩm của mình, bao gồm mô tả sản phẩm, hình ảnh và đánh giá của khách hàng.
- Chuyển đổi vector: Sử dụng mô hình học máy, chuyển đổi mô tả và hình ảnh của mỗi sản phẩm thành vector.
- Xây dựng cơ sở dữ liệu vector: Lưu trữ các vector này trong cơ sở dữ liệu vector và xây dựng một hệ thống truy xuất nhanh chóng.
- Xử lý truy vấn của người dùng: Khi người dùng nhập một từ khóa truy vấn, ví dụ: giày thể thao, hệ thống sẽ chuyển đổi truy vấn này thành vector và tìm kiếm vector tương tự nhất trong cơ sở dữ liệu vector.
- Trả về kết quả: Hệ thống sẽ chuyển đổi vector sản phẩm có độ tương đồng cao nhất trở lại thông tin sản phẩm và hiển thị cho người dùng.
Chúng ta sẽ sử dụng Python để chuyển đổi mô tả các khái niệm này. Hãy xem biểu đồ đầu tiên: biểu đồ chuyển đổi vector.
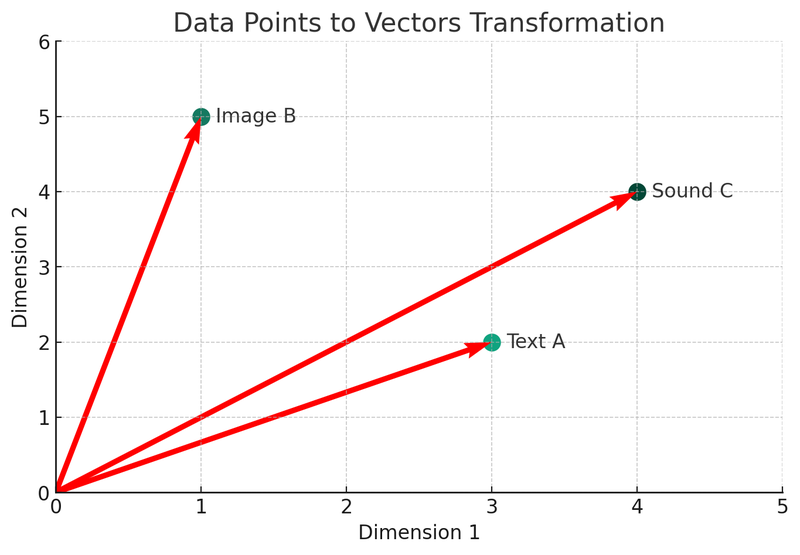
Trong hình minh họa này, chúng ta có thể thấy ba loại dữ liệu khác nhau (văn bản A, hình ảnh B, âm thanh C) được chuyển đổi thành dạng vector trong không gian hai chiều. Mỗi điểm đại diện cho một vector, tức là biểu diễn toán học của dữ liệu gốc. Quá trình này là cốt lõi của việc xây dựng chỉ mục và cơ chế truy xuất của cơ sở dữ liệu vector.
Tiếp theo, chúng ta sẽ vẽ biểu đồ thứ hai: biểu đồ không gian vector, cho thấy các điểm dữ liệu này (bây giờ là vector) được tập hợp trong không gian đa chiều theo độ tương đồng như thế nào.
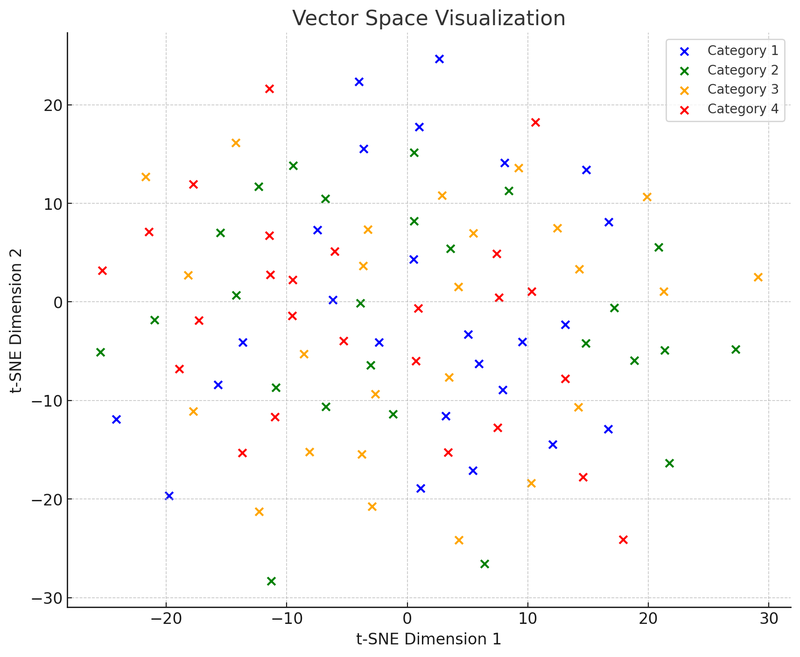
Trong hình minh họa trực quan không gian vector này, chúng ta sử dụng t-SNE (t-distributed Stochastic Neighbor Embedding), một kỹ thuật giảm chiều thường dùng, giúp chúng ta chiếu dữ liệu cao chiều vào không gian hai hoặc ba chiều để dễ dàng trực quan hóa. Biểu đồ này hiển thị 100 điểm dữ liệu (ban đầu trong không gian 50 chiều) được giảm chiều xuống không gian hai chiều sau khi phân bố. Giả sử các điểm này được chia thành bốn loại, mỗi loại được biểu thị bằng một màu khác nhau, việc trực quan hóa như vậy giúp hiểu cách cơ sở dữ liệu vector hoạt động: chúng có thể tập hợp các điểm dữ liệu tương tự (tức là vector) lại với nhau dựa trên khoảng cách tương đối giữa các điểm dữ liệu. Đặc điểm này khiến cơ sở dữ liệu vector có thể nhanh chóng tìm thấy các điểm "láng giềng" khi truy xuất, tức là những điểm dữ liệu tương tự nhất với truy vấn.
Để mô phỏng hệ thống gợi ý sản phẩm của công ty thương mại điện tử, chúng ta sẽ xây dựng một ví dụ đơn giản, bao gồm: một tập hợp các vector sản phẩm và một vector truy vấn của người dùng. Chúng ta sẽ thông qua hình ảnh hóa để hiển thị sự phân bố của các vector sản phẩm trong không gian vector và cách "vector truy vấn" của người dùng tìm thấy "vector sản phẩm gần nhất", để giải thích ứng dụng của cơ sở dữ liệu vector trong hệ thống gợi ý sản phẩm.
Phân tích trường hợp hình ảnh hóa
Trước tiên, tạo ra một tập hợp các vector sản phẩm mô phỏng, sau đó định nghĩa một vector truy vấn của người dùng. Tiếp theo, chúng ta sẽ
sử dụng một biểu đồ để hiển thị cách vector truy vấn này định vị trong không gian vector và tìm thấy vector sản phẩm gần nhất.
Hãy bắt đầu quá trình này.
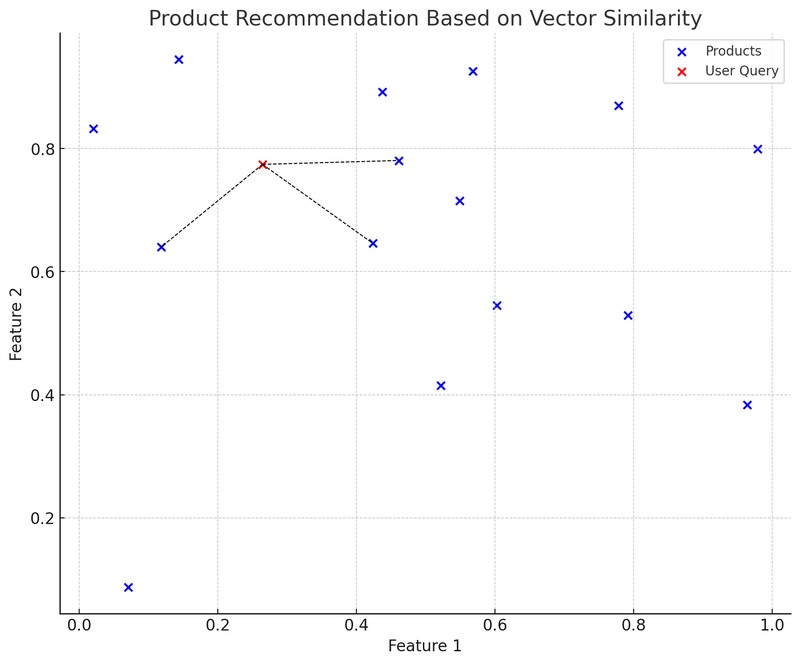
Trong biểu đồ này, các điểm màu xanh đại diện cho các sản phẩm trên nền tảng thương mại điện tử, mỗi sản phẩm có một vector đặc trưng hai chiều. Điểm màu đỏ là một truy vấn của người dùng, truy vấn này cũng được chuyển đổi thành một vector hai chiều. Chúng ta sử dụng cấu trúc dữ liệu K-D tree (KDTree) để nhanh chóng tìm ra "vector sản phẩm gần nhất với truy vấn của người dùng".
Trong biểu đồ, đường nối từ vector truy vấn của người dùng (điểm đỏ) đến vector sản phẩm gần nhất (đường nét đứt màu đen) biểu thị: hệ thống gợi ý sẽ dựa trên độ tương đồng giữa các vector để gợi ý các sản phẩm này cho người dùng. Đây là một ví dụ đơn giản về ứng dụng thực tế của cơ sở dữ liệu vector: người dùng đưa ra truy vấn, hệ thống chuyển đổi truy vấn thành vector và nhanh chóng tìm thấy vector sản phẩm tương tự nhất trong cơ sở dữ liệu vector, từ đó gợi ý sản phẩm liên quan cho người dùng.
Ưu điểm của phương pháp này là tốc độ gợi ý nhanh và tương đối chính xác, vì nó dựa trên tính toán đặc trưng của sản phẩm, chứ không chỉ đơn thuần là đối sánh từ khóa. Thách thức bao gồm: làm thế nào để chọn và điều chỉnh vector đặc trưng để mô tả và biểu diễn tốt nhất đặc điểm sản phẩm, cũng như cách xử lý vấn đề "khởi động lạnh" (Cold Start) đối với sản phẩm mới hoặc truy vấn ít gặp.
Kết luận
Trong môi trường kinh doanh hiện nay, nơi quyết định dựa trên dữ liệu, cơ sở dữ liệu vector xử lý và truy xuất một lượng lớn dữ liệu đa chiều theo cách độc đáo và mạnh mẽ, khiến chúng trở thành lựa chọn lý tưởng cho ứng dụng trí tuệ nhân tạo và học máy. Từ việc cải thiện mức độ liên quan của kết quả tìm kiếm đến thúc đẩy gợi ý sản phẩm cá nhân hóa, cơ sở dữ liệu vector đang nhanh chóng trở thành công cụ quý giá cho các kỹ sư dữ liệu và nhà sáng tạo công nghệ trong mọi ngành công nghiệp. Thông qua hình ảnh và phân tích trường hợp của Appar Technologies, hy vọng có thể giải thích rõ ràng cho bạn cách cơ sở dữ liệu vector hoạt động và tại sao chúng có thể cung cấp kết quả nhanh chóng và chính xác như vậy.
Cơ sở dữ liệu vector đã cho thấy khi con người hiểu và sử dụng dữ liệu theo cách mới, có thể tạo ra những công cụ và ứng dụng mạnh mẽ đến mức nào. Với sự phát triển liên tục của công nghệ, chúng ta có thể kỳ vọng cơ sở dữ liệu vector sẽ đóng vai trò quan trọng hơn trong công việc xử lý và phân tích dữ liệu trong tương lai.
Nếu bạn quan tâm đến cách AI tạo ra bài viết chất lượng cao, tích hợp mô hình ngôn ngữ lớn vào sản phẩm hoặc quy trình nội bộ của doanh nghiệp, có thể liên hệ với chuyên gia AI tạo sinh Appar Technologies, hello@appar.com.tw để đặt lịch tư vấn.