向量数据库是什么?
By Sean Chen, 2023年11月10日

本系列文章为“让 AI 解释 AI”,全文由 GPT-4 等大语言模型在人为监督下撰写。本系列以深入浅出的方式,让不同背景的工作者皆能轻松补给 AI 相关知识。前段为解释该知识点对商业面的意义,后段解释较深入的技术细节。
当业务遇上大数据时代的来临,向量数据库便成为非结构化数据资料里的一盏明灯,照亮快速信息检索之路。这篇文章将带您深入了解这项技术如何运作,以及它对企业界的意义与影响。
向量数据库的原理和本质
向量数据库使用了数学中的“向量”来储存信息。让我们举个生活中的例子来做说明:假设您的房间里有很多不同颜色的小球,每个小球代表一种数据。现在,您想要把小球放到书架上的特定位置,而且这些位置要能够反映出每个小球的颜色特性。于是,您决定使用一本“颜色地图”笔记来帮助你找到每个小球的位置。在这本笔记上,相似颜色的小球会被放得比较靠近彼此;而不同颜色的则会放得远一点。
向量数据库即是相同的原理,它先将各种数据(像是文字、图片或声音)转换成数学上的向量(就像刚刚提到的小球)。这些向量,有着自己在多维空间中的位置,就像是在书架上的小球。当您想要快速找到与某个数据最相似的其他数据时,向量数据库会帮您在这个多维空间中,找出位置最接近的向量(就好像找出颜色最相近的小球那样)。
简单来说,就是通过数学上的方法,将数据的特征抽象化成空间中的点,然后通过计算这些点之间的距离,来快速找出相似的数据。
为什么重要
想象一下,您正在一间大型的图书馆寻找一本特定的书,如果每本书都只能按照作者或标题来排列,您可能需要花费大量时间去查找。但如果书籍是按照“内容相关性”来排列,那么您想要的书,就会和相似主题的书本放在一起,这样找起来就快多了。这就是向量数据库的重要性所在:它们可以极大地提高查找和分析大量数据的效率。
如何使用
使用向量数据库时,首先要有一组数据,比如文本、图像或声音。这些数据会通过“机器学习模型”转换成“向量”。然后,这些向量储存在向量数据库中。当用户提出查询时,该查询同样被转换成向量,数据库会快速地找出与这个查询向量最接近的数据向量,从而找到用户需要的信息。
应用
向量数据库被各行各业里需要处理大量数据的公司所使用。这包括了科技公司、金融机构、医疗保健机构,甚至是零售商。任何需要从“茫茫难以结构化的数据大海里,快速找到所需信息的组织”都可能会使用向量数据库。
优势
向量数据库的优势在于它的高效率和准确性。它可以快速处理和检索大量的复杂数据,这在使用传统数据库时往往是不可能的。此外,向量数据库在处理模糊查询方面也非常出色,这对于机器学习和人工智能应用至关重要。
挑战
需要大量的计算资源,特别是在处理非常大的数据集时。其次,它们需要高度专业化的知识来设置和维护。最后,数据的隐私和安全性也是一个重要的考量点。
对向量数据库有了基本了解后,接下来让我们以图表与实际案例,来更加具体地了解向量数据库的运作吧!
通过视觉化图表,来场向量数据库的介绍
我们从基本的概念图开始,来解释向量数据库的运作原理,再进行一个具体的案例分析。以下是对这两个部分的描述:
运作原理的图表解释
- 向量转换图:该图表展示如何将文本、图像或声音数据转换成向量。
- 向量空间图表:在多维空间中,每个点都代表一个向量,该图表将展示这些点是如何根据相似度被聚集在一起的。我们可以用不同颜色的点来表示不同类别的数据。
- 查询处理流程图表:从用户输入查询到获得结果,这个流程图将展示整个检索过程。这会包含用户查询的输入、转换为向量的过程、向量在数据库中的匹配过程,以及最终回传给用户的相似结果。
具体案例分析
假设有一家电商公司,他们想提高其“产品推荐系统”的准确度和效率,目标是当用户搜索产品时,能够快速找到并推荐最相关的产品。
案例执行步骤:
- 数据收集:公司从其产品数据库中收集数据,包括产品描述、图片和客户评价。
- 向量转换:使用机器学习模型,将每个产品的描述和图片转换成向量。
- 向量数据库建立:将这些向量储存在向量数据库中,并建立一个快速检索系统。
- 用户查询处理:当用户输入一个关键词查询,例如:运动鞋,系统就把这个查询转化为向量,并在向量数据库中查找最相似的向量。
- 回传结果:系统将相似度最高的产品向量转化回产品信息,并展示给用户。
我们将使用 Python 转换描述这些概念。让我们看看第一张图表:向量转换图。
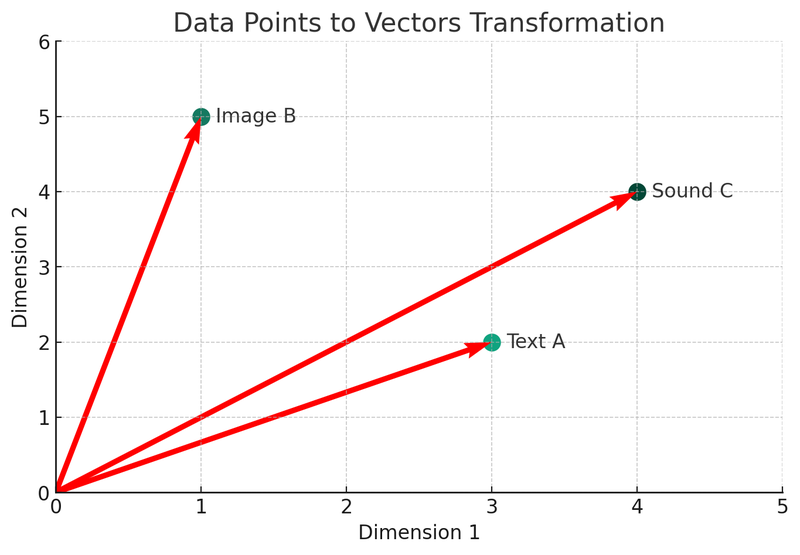
在这张插图中,我们可以看到三种不同的数据类型(文本 A、图像 B 、声音 C)被转化成二维空间中的向量模样。每个点代表了一个向量,即原始数据的数学表示方式。这个过程是向量数据库建立索引和检索机制的核心。
接下来,我们将绘制第二个图表:向量空间图,展示这些数据点(现在是向量)是如何在多维空间中按照相似度聚集的。
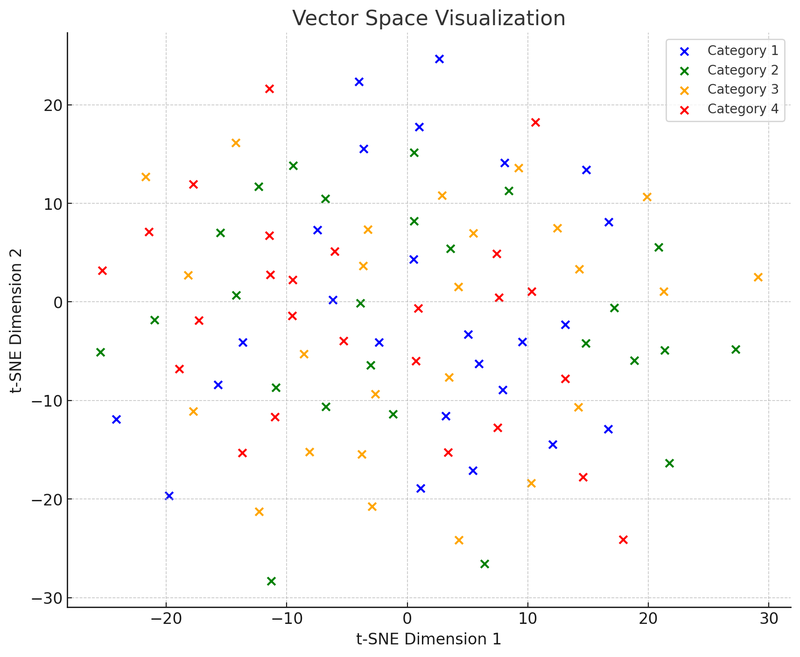
在这个向量空间视觉化的插图中,我们使用了 t-SNE(t-distributed Stochastic Neighbor Embedding),这是一种常用的降维技术,它能够帮助我们将高维数据投影到二维或三维空间,以便于视觉化。这张图表显示了100个数据点 (原本在50维空间中)被降维到二维空间后的分布情况。假设这些点分为四个类别,每个类别用不同的颜色表示,这样的视觉化有助于理解向量数据库是如何运作的:它们能够根据数据点(即向量)之间的相对距离,将相似的数据点聚集在一起。这个特性使得向量数据库在检索时可以非常迅速地找到“邻居”点,也就是那些与查询最相似的数据点。
为了模拟电子商务公司的产品推荐系统,我们将建立一个简化的范例,其中包含:一组产品向量和一个用户的查询向量。我们将通过图像化展示这些产品向量在向量空间中的分布以及用户的“查询向量”如何找到“最接近的产品向量”,来说明向量数据库在产品推荐系统中的应用。
图像化的案例分析
首先,生成一组模拟的产品向量,然后定义一个用户查询向量。接着我们会
用一个图表展示这个查询向量如何在向量空间中定位并找到最近邻的产品向量。
让我们开始这个过程。
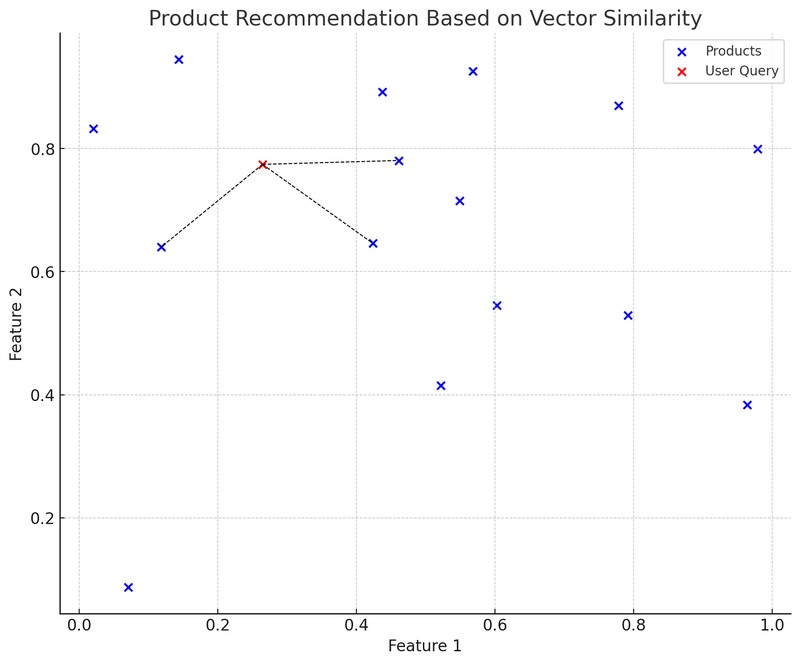
在这张图表中,蓝点代表电商平台上的各个产品,每个产品都有一个二维特征向量。红点是一个用户的查询,这个查询同样被转化为一个二维向量。我们使用了 K-D 树(KDTree)这个数据结构来快速找出与“用户查询最接近的产品向量”。
在图中,从用户查询向量(红点)到最近邻产品向量的连线(黑色虚线)表示:推荐系统会根据向量间的相似度为用户推荐这些产品。这就是向量数据库在实际应用中的一个简化范例:用户提出查询,系统将查询转化为向量,并在向量数据库中快速找到最相似的产品向量,从而推荐相关产品给用户。
这种方法的优势是推荐的速度快且相对准确,因为它是基于产品特征的数学计算,而不仅仅是关键词匹配。挑战则包括:如何选择和调整特征向量以最好地描述、表示产品特性,以及如何处理新上架的产品或较少见查询的“冷启动”(Cold Start)问题。
结论
在现今数据驱动决策的商业环境中,向量数据库以独特且强大的方式处理和检索大量的多维数据,使得它们成为人工智能和机器学习应用的理想选择。从提高搜索结果的关联性到推动个性化的产品推荐,向量数据库正迅速成为各行各业数据工程师和科技创新者的宝贵工具。通过约沛科技的插图和案例分析,希望可以为您清楚地说明向量数据库是如何运作的,以及它们为何能提供如此快速和准确的结果。
向量数据库展现了当人们以新的方式来理解和利用数据时,能够创造出多么强大的工具和应用。随着技术的持续发展,我们可以期待向量数据库将在未来的数据处理和分析工作中发挥更加关键的作用。
如对生成式 AI 如何产生高质量文章、整合大语言模型至产品或是企业内部流程有兴趣,可联系生成式 AI 专家 约沛科技, hello@appar.com.tw 预约咨询。