向量資料庫是什麼?
By Sean Chen, 2023年11月10日

本系列文章為「讓 AI 解釋 AI 」,全文由 GPT-4 等大語言模型在人為監督下撰寫。本系列以深入潛出的方式,讓不同背景的工作者皆能輕鬆補給 AI 相關知識。前段為解釋該知識點對商業面的意義,後段解釋較深入的技術細節。
當業務遇上大數據時代的來臨,向量資料庫便成為非結構化數據資料裡的一盞明燈,照亮快速訊息檢索之路。這篇文章將帶您深入了解這項技術如何運作,以及它對企業界的意義與影響。
向量資料庫的原理和本質
向量資料庫使用了數學中的「向量」來儲存資訊。讓我們舉個生活中的例子來做說明:假設您的房間裡有很多不同顏色的小球,每個小球代表一種資料。現在,您想要把小球放到書架上的特定位置,而且這些位置要能夠反映出每個小球的顏色特性。於是,您決定使用一本「顏色地圖」筆記來幫助你找到每個小球的位置。在這本筆記上,相似顏色的小球會被放得比較靠近彼此;而不同顏色的則會放得遠一點。
向量資料庫即是相同的原理,它先將各種資料(像是文字、圖片或聲音)轉換成數學上的向量(就像剛剛提到的小球)。這些向量,有著自己在多維空間中的位置,就像是在書架上的小球。當您想要快速找到與某個資料最相似的其他資料時,向量資料庫會幫您在這個多維空間中,找出位置最接近的向量(就好像找出顏色最相近的小球那樣)。
簡單來說,就是透過數學上的方法,將資料的特徵抽象化成空間中的點,然後透過計算這些點之間的距離,來快速找出相似的資料。
為什麼重要
想像一下,您正在一間大型的圖書館尋找一本特定的書,如果每本書都只能按照作者或標題來排列,您可能需要花費大量時間去查找。但如果書籍是按照「內容相關性」來排列,那麼您想要的書,就會和相似主題的書本放在一起,這樣找起來就快多了。這就是向量資料庫的重要性所在:它們可以極大地提高查找和分析大量數據的效率。
如何使用
使用向量資料庫時,首先要有一組數據,比如文本、圖像或聲音。這些數據會透過「機器學習模型」轉換成「向量」。然後,這些向量儲存在向量資料庫中。當使用者提出查詢時,該查詢同樣被轉換成向量,資料庫會快速地找出與這個查詢向量最接近的數據向量,從而找到使用者需要的訊息。
應用
向量資料庫被各行各業裡需要處理大量數據的公司所使用。這包括了科技公司、金融機構、醫療保健機構,甚至是零售商。任何需要從「茫茫難以結構化的數據大海裡,快速找到所需資訊的組織」都可能會使用向量資料庫。
優勢
向量資料庫的優勢在於它的高效率和準確性。它可以快速處理和檢索大量的複雜數據,這在使用傳統資料庫時往往是不可能的。此外,向量資料庫在處理模糊查詢方面也非常出色,這對於機器學習和人工智慧應用至關重要。
挑戰
需要大量的計算資源,特別是在處理非常大的數據集時。其次,它們需要高度專業化的知識來設置和維護。最後,數據的隱私和安全性也是一個重要的考量點。
對向量資料庫有了基本瞭解後,接下來讓我們以圖表與實際案例,來更加具體地了解向量資料庫的運作吧!
透過視覺化圖表,來場向量資料庫的介紹
我們從基本的概念圖開始,來解釋向量資料庫的運作原理,再進行一個具體的案例分析。以下是對這兩個部分的描述:
運作原理的圖表解釋
- 向量轉換圖:該圖表展示如何將文本、圖像或聲音數據轉換成向量。
- 向量空間圖表:在多維空間中,每個點都代表一個向量,該圖表將展示這些點是如何根據相似度被聚集在一起的。我們可以用不同顏色的點來表示不同類別的數據。
- 查詢處理流程圖表:從使用者輸入查詢到獲得結果,這個流程圖將展示整個檢索過程。這會包含使用者查詢的輸入、轉換為向量的過程、向量在資料庫中的媒合過程,以及最終回傳給使用者的相似結果。
具體案例分析
假設有一家電商公司,他們想提高其「產品推薦系統」的準確度和效率,目標是當使用者搜索產品時,能夠快速找到並推薦最相關的產品。
案例執行步驟:
- 數據收集:公司從其產品資料庫中收集數據,包括產品描述、圖片和客戶評價。
- 向量轉換:使用機器學習模型,將每個產品的描述和圖片轉換成向量。
- 向量資料庫建立:將這些向量儲存在向量資料庫中,並建立一個快速檢索系統。
- 使用者查詢處理:當使用者輸入一個關鍵字查詢,例如:運動鞋,系統就把這個查詢轉化為向量,並在向量資料庫中查找最相似的向量。
- 回傳結果:系統將相似度最高的產品向量轉化回產品訊息,並展示給使用者。
我們將使用 Python 轉換描述這些概念。讓我們看看第一張圖表:向量轉換圖。
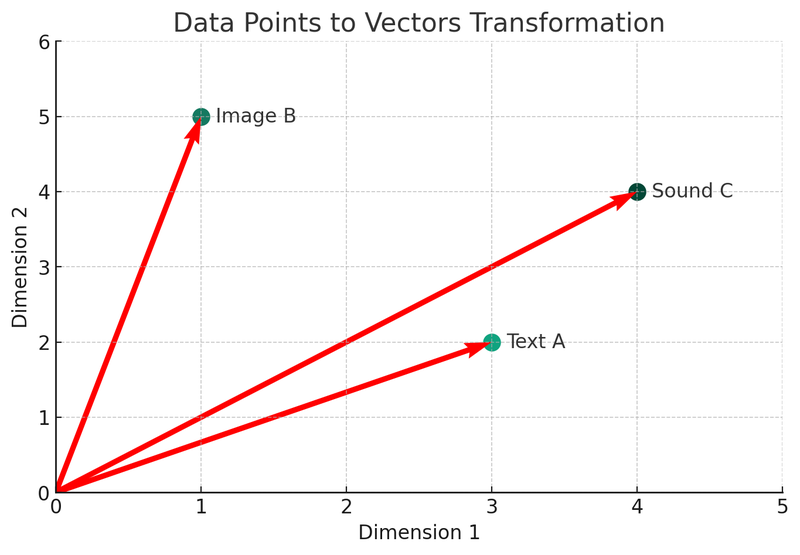
在這張插圖中,我們可以看到三種不同的數據類型(文本 A、圖像 B 、聲音 C)被轉化成二維空間中的向量模樣。每個點代表了一個向量,即原始數據的數學表示方式。這個過程是向量資料庫建立索引和檢索機制的核心。
接下來,我們將繪製第二個圖表:向量空間圖,展示這些數據點(現在是向量)是如何在多維空間中按照相似度聚集的。
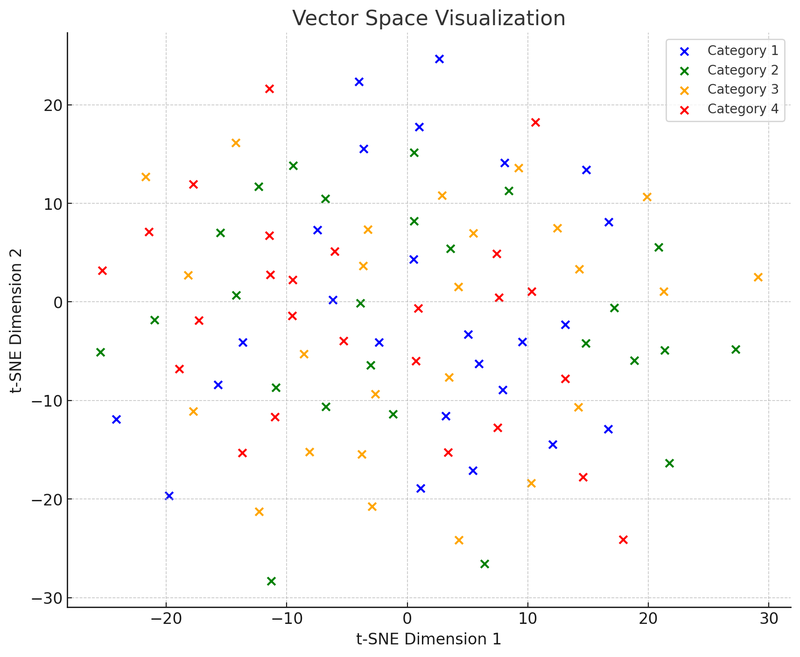
在這個向量空間視覺化的插圖中,我們使用了 t-SNE(t-distributed Stochastic Neighbor Embedding),這是一種常用的降維技術,它能夠幫助我們將高維數據投影到二維或三維空間,以便於視覺化。這張圖表顯示了100個數據點 (原本在50維空間中)被降維到二維空間後的分佈情況。假設這些點分為四個類別,每個類別用不同的顏色表示,這樣的視覺化有助於理解向量資料庫是如何運作的:它們能夠根據數據點(即向量)之間的相對距離,將相似的數據點聚集在一起。這個特性使得向量資料庫在檢索時可以非常迅速地找到「鄰居」點,也就是那些與查詢最相似的數據點。
為了模擬電子商務公司的產品推薦系統,我們將建立一個簡化的範例,其中包含:一組產品向量和一個使用者的查詢向量。我們將透過圖像化展示這些產品向量在向量空間中的分佈以及使用者的「查詢向量」如何找到「最接近的產品向量」,來說明向量資料庫在產品推薦系統中的應用。
圖像化的案例分析
首先,生成一組模擬的產品向量,然後定義一個使用者查詢向量。接著我們會
用一個圖表展示這個查詢向量如何在向量空間中定位並找到最近鄰的產品向量。
讓我們開始這個過程。
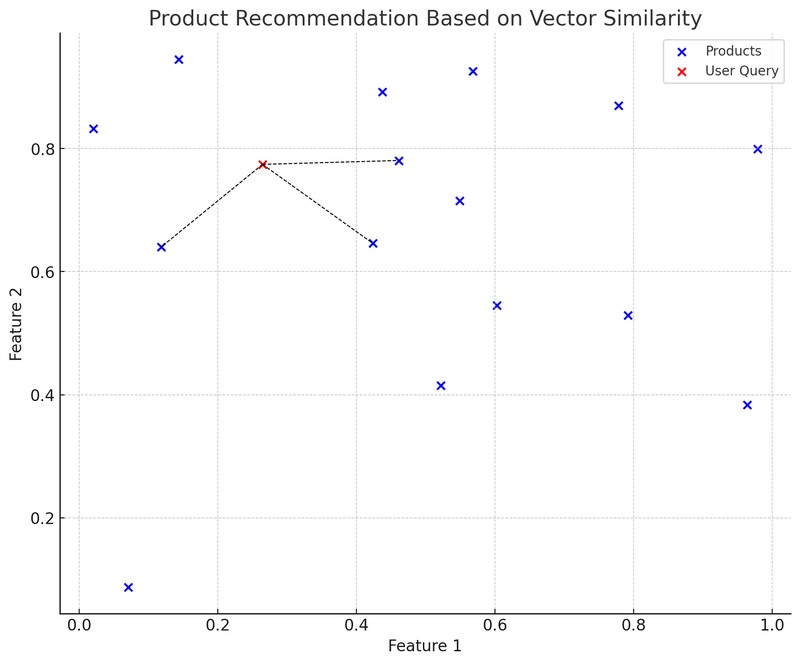
在這張圖表中,藍點代表電商平台上的各個產品,每個產品都有一個二維特徵向量。紅點是一個使用者的查詢,這個查詢同樣被轉化為了一個二維向量。我們使用了 K-D 樹(KDTree)這個資料結構來快速找出與「使用者查詢最接近的產品向量」。
在圖中,從使用者查詢向量(紅點)到最近鄰產品向量的連線(黑色虛線)表示:推薦系統會根據向量間的相似度為使用者推薦這些產品。這就是向量資料庫在實際應用中的一個簡化範例:使用者提出查詢,系統將查詢轉化為向量,並在向量資料庫中快速找到最相似的產品向量,從而推薦相關產品給使用者。
這種方法的優勢是推薦的速度快且相對準確,因為它是基於產品特徵的數學計算,而不僅僅是關鍵字媒合。挑戰則包括:如何選擇和調整特徵向量以最好地描述、表示產品特性,以及如何處理新上架的產品或較少見查詢的「冷啟動」(Cold Start)問題。
結論
在現今數據驅動決策的商業環境中,向量資料庫以獨特且強大的方式處理和檢索大量的多維數據,使得它們成為人工智慧和機器學習應用的理想選擇。從提高搜索結果的關聯性到推動個性化的產品推薦,向量資料庫正迅速成為各行各業資料工程師和科技創新者的寶貴工具。透過約沛科技的插圖和案例分析,希望可以為您清楚地說明向量資料庫是如何運作的,以及它們為何能提供如此快速和準確的結果。
向量資料庫展現了當人們以新的方式來理解和利用數據時,能夠創造出多麼強大的工具和應用。隨著技術的持續發展,我們可以期待向量資料庫將在未來的數據處理和分析工作中發揮更加關鍵的作用。
如對生成式 AI 如何產生高品質文章、整合大語言模型至產品或是企業內部流程有興趣,可聯繫生成式 AI 專家 Appar Technologies, hello@appar.com.tw 預約諮詢。










